用python美丽汤爬虫抓取网页中自己的姓名怎么弄代码?
只抓取网页中的文字,不需要图片链接什么的,说是只需要15行代码就可以做到,代码应该怎么写?
爬取题主问题中的名字,自己改下css选择器
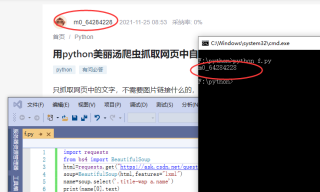
import requests
from bs4 import BeautifulSoup
html=requests.get("https://ask.csdn.net/questions/7578578",headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36 Edg/96.0.1054.29'}).text
soup=BeautifulSoup(html,features="lxml")
name=soup.select('.title-wap a.name')#自己改下css选择器
print(name[0].text)
有帮助麻烦点下【采纳该答案】,谢谢~~有其他问题可以继续交流~
import requests
from bs4 import BeautifulSoup
response = requests.get('https://www.autohome.com.cn/news/')
response.encoding = response.apparent_encoding
response.text
soup = BeautifulSoup(response.text,features='html.parser')
# 直接用soup.find(id='xxx') 简单又好记
# soup的每一个find的return可以继续用find, find是找到第一个,
# find_all 是所有,返回list
target = soup.find(id='auto-channel-lazyload-article')
li_list = target.find_all('li')
for i in li_list:
a = i.find('a')
if a:
print(a.attrs.get('href'))
txt = a.find('h3').text
print(txt)
img_url = 'https:' + a.find('img').attrs.get('src')
print(img_url)
img_response = requests.get(url=img_url)
import uuid
file_name = str(uuid.uuid4()) + '.jpg'
with open(file_name,'wb') as f:
f.write(img_response.content)
代码结构类似这样
哈哈哈哈,,,,你搞掂了没?
有什么疑问可以来找我