python爬虫解析html的一个问题
解析html的一个问题

我需要爬取这里的文字
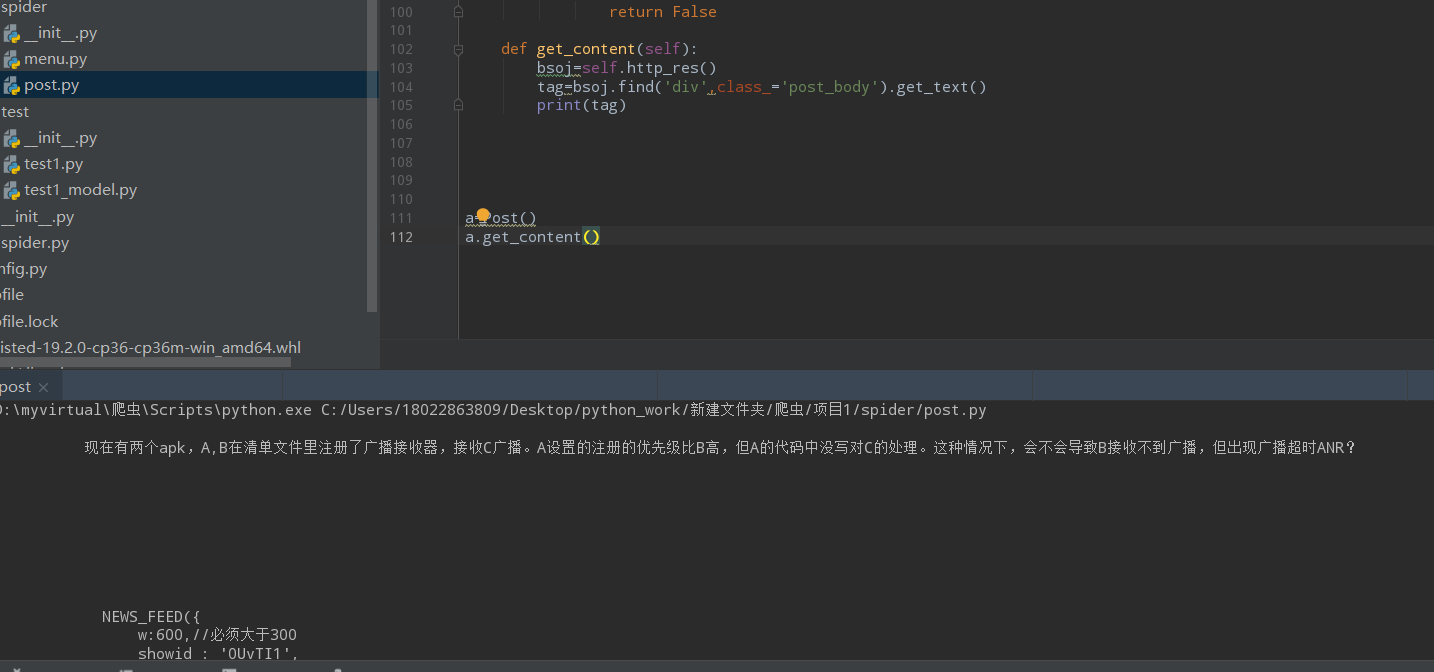
但是爬取出来后多了一段东西,这个是什么,应该怎么处理掉它
看上去这些内容是网页本来就有的,爬虫代码没有问题。
你可以用正则表达式自己再过滤下。这段内容前面似乎有很多连续的换行,可以作为特征。
两种可能:一种是存在两个相同class的<div>; 还有一种是<div>存在别的下级标签,范围过大就把所有文本拿到了
解决方法如果是第一种,你就看看每个页面是不是固定的,固定的话直接取第二个就行;第二种方法类似,你把下级标签包含进去就行