js爬取网页中的文字内容
问题遇到的现象和发生背景
sh软工it
在X站看视频用wx开发者工具开发手把手做,最后一步卡住了
我需要的是网页中的文字部分,爬出的data却包含了整个网页源代码
问题相关代码,请勿粘贴截图
onLoad: function (options) {
wx.request({
url: 'https://gengbaike.cn/',
success:(res=>{
console.log(res);
this.setData({
recommendMemes:res.date
})
})
})
},
运行结果及报错内容
{data: "<!DOCTYPE html>
↵<html>
↵<head>
↵ <meta charset…
↵ }
↵ });
↵</script>
↵</body>
↵</html>", header: {…}, statusCode: 200, cookies: Array(2), errMsg: "request:ok"}
cookies: (2) ["PHPSESSID=j258tkddbvk3ocvbpetksl15f1; path=/; HttpOnly", "hd_sid=ouCvqs; expires=Mon 21-Nov-2022 02:22:37 GMT; Max-Age=31536000; path=/; httponly"]
data: "<!DOCTYPE html>
↵<html>
↵<head>
↵ <meta charset"
errMsg: "request:ok"
header: {Server: "wts/1.6.4", Date: "Sun, 21 Nov 2021 02:22:37 GMT", Content-Type: "text/html; charset=UTF-8", Transfer-Encoding: "chunked", Connection: "keep-alive", …}
statusCode: 200
__proto__: Object
我的解答思路和尝试过的方法
根本看不懂
我想要达到的结果
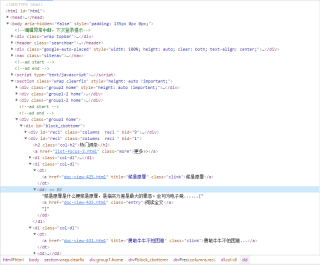
我只要dt和dd里的内容啊
你先看下你要的数据是否就是直接在html页面里的。有的页面数据是通过json等接口写回页面的
思路没错,
如果需要内容,需要在响应中进行数据提取操作