命名实体识别程序改进
想要在识别的时候把人名和机构名区分开,
这个程序的运行结果是正确的,
但是我的程序只能用两次for循环,用and结果是错误的,请问怎么把两次for循环简化一下
fromstanfordcoren1pimport StanfordCoreNLP
path=r"E:\ctt\stanford-corenlp-4.1.0"
nlp = StanfordCoreNLP(path,1ang="zh”)
sentence=“中央广播电视王小明去北京上大学,他将在北京大学学习四年。”
r = nlp.ner(sentence)
nlp.close()
print("Named Entities:”, r)
tmp=
for w, t in r:
if t!="ORGANIZATION":
if tmp:
print(tmp)
tmp=
continue
tmp += w
else:
if tmp:
print(tmp)
for w,t in r:
if t!=“PERSON”:
if tmp:
print(tmp)
tmp=
continue
tmp += w
else:
if tmp:
print(tmp)
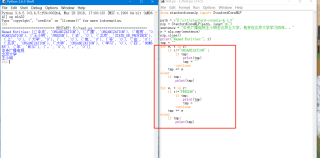
如果仅仅是区分开的话,是不是可以考虑下字典形式:
r=[('中央','ORGANIZATION'),('广播','ORGANIZATION'),('电视','ORGANIZATION'),('主小明','PERSON'),('去','0'),('北京','STATE_OR_PROVINCE')]
dic={}
for value,key in r:
dic.setdefault(key, []).append(value)
print(dic)
输出:
{'ORGANIZATION': ['中央', '广播', '电视'], 'PERSON': ['主小明'], '0': ['去'], 'STATE_OR_PROVINCE': ['北京']}
不知能否帮助你