正则表达式无法匹配在单词末尾的特殊字符,求专家解释!
给国外的前端页面对应的配置文件里面写了个脏话列表,
今天发现有的单词不能够成功匹配成脏话,
后面测试了一些数据,发现这些单词有些共同点就是单词最后一个位置上有特殊的字符,
例如:
cipką
cipkę
dojebać
dojebał
dojebię
dopieprzać
当这些字符 ą ę ć ł在单词中间时,可以匹配成脏话,例如zajebała能够成功识别成脏话,但是上述这种就不行
正则表达式如下:^((?!\b(chuj|chuja|zesrywać|zesrywća)\b)(\s|\S))*$
第一次:
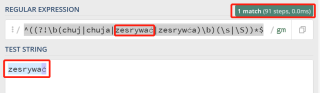
第二次:
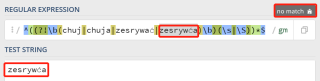
应该两次匹配都应该是同一种结果,但是因为字符位置的原因导致结果不一样
实在想不出哪里有问题,希望有懂底层的专家能解释一波该怎么解决,感谢了!
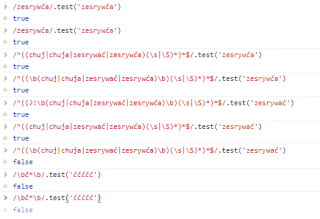
\b 只能识别英文单词边界,其他语言的单词边界是无法识别的
貌似应该用哈希表啊?
有些地方叫字典。
在字典里的词是脏话,所以,需要先词法分析,把输入串分解成一个个单词,再把单词去字典里找。
词法分析用正则表达式完成即可。