才照着敲的爬虫代码,但是没有输出结果
能够抓取到源代码,但是打印输出却没有内容,问题出在哪里了,改不出来
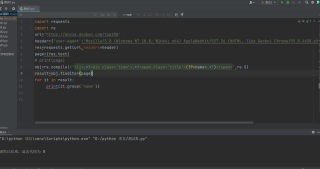
其实是你正则匹配中写错了,正确的是这样的
代码如下:
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>', re.S)
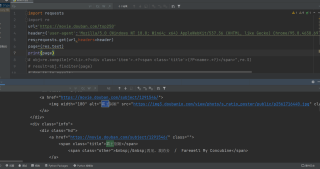
这里改一下就好了,因为在网页中,div class="item"中的class标签中,是没有单引号的,只有双引号,改成双引号就好了
url = 'https://movie.douban.com/top250'
header = {
# 填自己的ua
}
res = requests.get(url, headers=header)
page = res.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(.*?)</span>', re.S)
for i in obj.finditer(page):
print(i.group(1))
如果有用的话,请点采纳,谢谢
前面当我没说,没数据是因为你正则写错了,你把单引号该为双引号
你把?P《name》去掉,然后print(it.group('name')),改成print(it.group(1))试试