如何用python将两列数字打乱但仍旧相互对应
首先,从txt中读取了500组数字,每组有两个数字(也就是500行两列),然后将这两列数字分开并打乱,但打乱后每一行的数字仍要保持对应关系
例如: 0.1 0.2 这一对数字原来在第1行,打乱之后在第8行,但是分别在两个list中
你好,我也遇到过这样的需求,不知道楼主的要求是不是和我理解的相同。
整理了一下我当时的思路,代码如下:
"""
File: test.py
将两列数字打乱但仍旧相互对应。
思路是,在打乱顺序之前,把其中一个列表(比如 l1)的元素位置记录下下来(比如,记到 index
中),打乱 l1 的顺序就之后(记为 l1_2),用 l1_2 和 index 的信息重排 l2 中的元素,恢复
二者的对应关系。
列表中的元素可以是数字、字符串。
运行:python3 test.py
"""
def create_index(lst):
""" 为给定 list 对象生成索引并返回。
索引的作用是记录 list 对象中每个元素的位置。
参数:
lst :一个 list 对象。
返回:
dict 对象
"""
index = {}
for i,v in enumerate(lst):
index[v] = i
return index
def applay_permutation(lst1, index1, lst2):
""" 根据 lst1 现在的顺序和 lst1 原来的索引,恢复 lst2 和 lst1 中元素的对应关系。
"""
lst3 = [lst2[index1[v]] for v in lst1]
return lst3
def main():
""" 测试
"""
# 两个具有对应关系的列表
l1=list("ABC")
l2=list("abc")
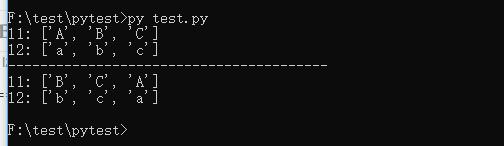
print("l1:", l1)
print("l2:", l2)
# 创建索引
index1=create_index(l1)
# 模拟 l1 顺序被打乱的情况
l1=list("BCA")
# 恢复 l1 和 l2 元素的对应关系
l2=applay_permutation(l1, index1, l2)
print("-"*40)
print("l1:", l1)
print("l2:", l2)
if __name__ == "__main__":
main()
先将文件读入一个列表,每行作为列表的一个元素
然后打乱列表顺序
再讲列表中的元素分割 分别保存到各自的一个列表中就可以了
最简单的,将 list(range(0,499)) 打乱
然后循环依次取你 txt装入数组,以打乱后的每个数字作为下标