PyODPS节点实现结巴中文分词(使用第三方包)
官方链接:https://help.aliyun.com/document_detail/126288.htm?spm=a2c4g.11186623.0.0.6f207ad6I5FuIk#task-1079380
我安装这个链接在自己的dataworks里测试,发现报错
不知道怎么处理
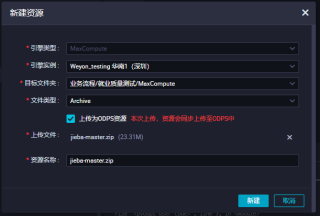
这么弄,也保存了
运行时:
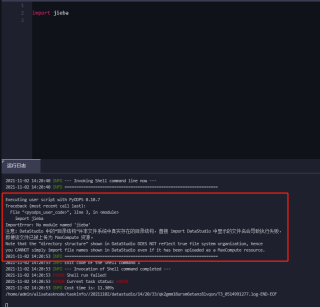
报错,求帮助
官方文档里面有使用教程啊,不是直接import,要加载libraries
def test(input_var):
import jieba
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
result=jieba.cut(input_var, cut_all=False)
return "/ ".join(result)
hints = {
'odps.isolation.session.enable': True
}
libraries =['jieba-master.zip'] #引用您的jieba-master.zip压缩包。
iris = o.get_table('jieba_test').to_df() #引用您的jieba_test表中的数据。
example = iris.chinese.map(test).execute(hints=hints, libraries=libraries)
print(example) #查看分词结果,分词结构为MAP类型数据。