dataframe 如何筛选相同两项的某一列中的值等于另一列中的值?
有下面这样一个表格:
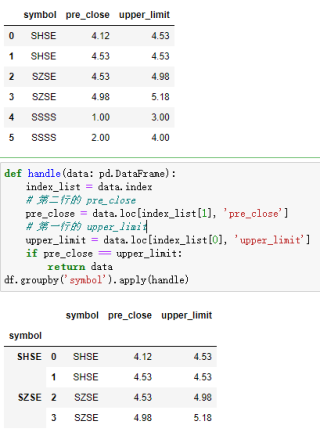
symbol pre_close upper_limit
0 SHSE.600683 4.12 4.53
1 SHSE.600683 4.53 4.98
2 SZSE.002385 4.53 4.98
3 SZSE.002385 4.98 5.48
4 SZSE.002676 3.14 3.45
5 SZSE.002676 3.14 3.45
6 SZSE.002972 18.21 20.03
7 SZSE.002972 20.03 22.03
symbol每两个一组,要筛选出每一组内第二行的pre_close等于第一行的upper_limit的所有行,实际意义是,先获取到了每个股票昨天和前天的收盘价以及涨停价,现在要选出昨天涨停的所有股票,这个用python怎么写最高效简单呢?
尝试了一下,算不上高效,勉强实现筛选
def handle(data: pd.DataFrame):
index_list = data.index
# 第二行的 pre_close
pre_close = data.loc[index_list[1], 'pre_close']
# 第一行的 upper_limit
upper_limit = data.loc[index_list[0], 'upper_limit']
if pre_close == upper_limit:
return data
df.groupby('symbol').apply(handle)
df.groupby('symbol').apply(lambda x: x if x['pre_close'] == x['upper_limit'].shift(1) else None)
我想通过这样一条语句实现,但是报错。问题出在哪儿呢?
df.groupby('symbol').apply(lambda x: x if x['pre_close'].to_list()[1] == x['upper_limit'].to_list()[0] else None)
搞定了,谢谢二位提供的思路,分享如下:
# 保留重复的项,以确保后面的过滤条件有效
df= df[df['symbol'].duplicated(keep=False)]
# 过滤出涨停的股票
df= df.groupby('symbol').filter(lambda x: (round(x['pre_close'].to_list()[1],2) == round(x['upper_limit'].to_list()[0],2)))