为什么用爬虫登陆网站时出现Forbidden, Please turn off CC?
初学爬虫,想要登陆一个网站,可是总是出现这个情况,啊啊啊,弄了好久了,感jio要爆炸了,求救求救
代码如下
import requests
data = {'pwuser':'**', 'pwpwd':'**'}
r = requests.post("http://www.sulanfund.com/bbs/login.php?", data=data)
print(r.text)
不知道怎么回事,去百度也找不到,求救~~~~~
对照浏览器的抓包结果看下,特别注意user-agent、cookie是否正确。如果浏览器也不行了,那么就是服务器有反爬的限制。
Forbidden, Please turn off CC
应该是服务器开启了防止cc攻击的功能
我这边用浏览器简单抓了一下包发现你少很多参数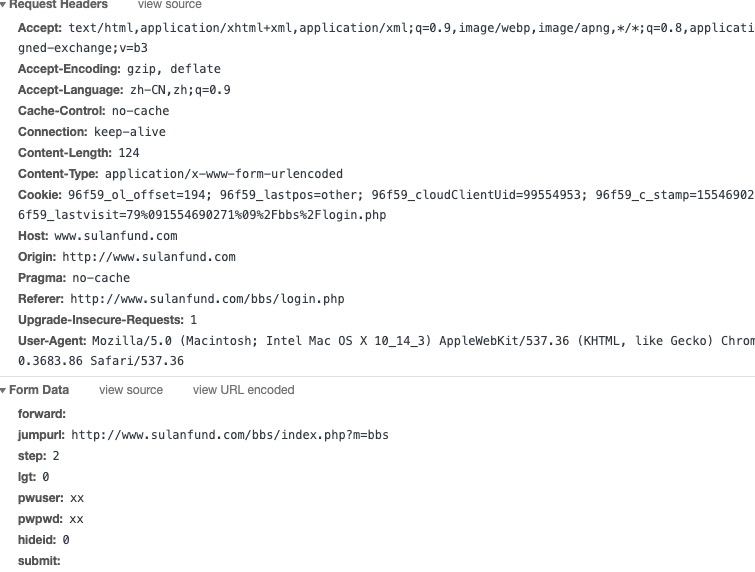
学爬虫之前要先学会抓包和分析交互协议