如果要获取<div>标签下的文本内容该怎么做呢?(用xpath,bs4,re中的一个都行)
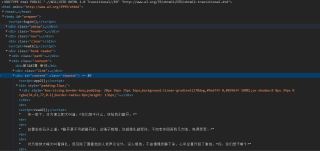
如果要获取
标签下的文本内容该怎么做呢?(用xpath,bs4,re中的一个都行)
鼠标右键复制xpath,然后在python中/text()或者.text获取文本内容,如图:

有帮助的话采纳一下哦!
通过div的Id获取内容
document.getElementById("ID").innerHTML;
用bs4的话可以这样试试:
txt=[x.text.strip() for x in soup.select('div.content')]
PS:问答VIP年卡 【限时加赠:IT技术图书免费领】,了解详情>>> https://vip.csdn.net/askvip?utm_source=1146287632