按照您爬取红木的代码,打印为空!
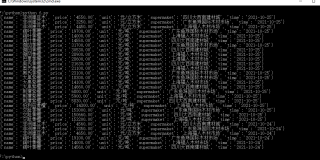
我这里跑没问题,题主代码出来看下,print(html)题主检查过有数据?有些时候反扒返回的也是html代码,但是不包含数据在里面的
import csv #用于把爬取的数据存储为csv格式,可以excel直接打开的
import time #用于对请求加延时,爬取速度太快容易被反爬
from time import sleep #同上
import random #用于对延时设置随机数,尽量模拟人的行为
import requests #用于向网站发送请求
from lxml import etree #lxml为第三方网页解析库,强大且速度快
url = 'http://yz.yuzhuprice.com:8003/findPriceByName.jspx?page.curPage=1&priceName=%E7%BA%A2%E6%9C%A8%E7%B1%BB'
headers = {
'User-Agent': "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
}
page = requests.get(url, headers=headers, timeout=10)
page.raise_for_status()
html = page.text
parse = etree.HTML(html) #解析网页
all_tr = parse.xpath('//*[@id="173200"]')
for tr in all_tr:
tr = {
'name': ''.join(tr.xpath('./td[1]/text()')).strip(),
'price': ''.join(tr.xpath('./td[2]/text()')).strip(),
'unit': ''.join(tr.xpath('./td[3]/text()')).strip(),
'supermaket': ''.join(tr.xpath('./td[4]/text()')).strip(),
'time': ''.join(tr.xpath('./td[5]/text()')).strip()
}
print(tr)
如果有正确页面信息返回,那就检查你的xpath是否正确,网页示例的代码是以前的,网站内容调整,一些节点及标签会变化的。
估计被反爬了