SQL nut in语句的实现原理是什么,为什么会出现那么多重复结果
select 顾客.顾客号,顾客.顾客姓名,顾客.邮编 from 主订单,顾客 where 顾客.顾客号 not in
(select 主订单.顾客号 from 主订单) and 顾客.城市='北京市' order by 顾客.邮编 desc
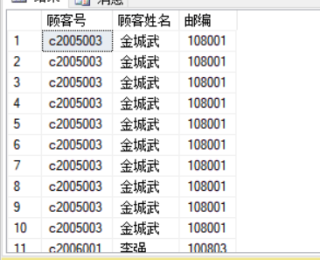
虽然知道distinct 可以去除重复结果,但是我想知道为什么会产生那么多重复结果
顾客表和主订单表的元素都是10个,每个结果元素重复个数也是10个,nut in的判断依据和原理是什么
如果是编程判断存在,那么我们也仅需要两个for或者while循环来判断,判断结果也不会出现那么多次重复。为什么这个会出现那么多重复
他是怎么完成判断的呢
两张表你用的是笛卡尔积查询。并没有建立两张表的关联。
也就是表1的10条数据会跟表2的10条数据,都进行连接,没有条件过滤,最后会得到100条记录。
你需要加上两张表之间的关联字段,比如说,顾客号作为关联字段。
查询顾客号相同的记录,如果顾客表和主订单表中的顾客号是唯一的,那么最后得到的结果就是唯一的,得到10条记录。
谢谢,问题已经解决,在本身没有重复元素的条件下出现重复结果,原来是因为笛卡儿积查询的原理。出现了mxn次的结果。
你看下主订单表或者顾客表里面有没有重复的数据,这种一般就是有重复的数据关联出来就有重复数据的情况。
出现重复数据,一般都是由于一对多或者多对多的数据关系造成你查询的数据重复的,
至于顾客.顾客号 not in
(select 主订单.顾客号 from 主订单)这个条件是指 顾客表里的 顾客号 不在主订单的顾客号里的数据,没有判断一句和原理,这个和你设计数据库结构以及存储的数据有关系,也就是说需要的数据得加上这个条件才能得到,所以才必须加上这个条件