csv表格合并统计的问题
最近初学python,想写一个小程序能合并不同表格并去除重复,例如

想统计这三个样本,‘
希望得到的理想状态是
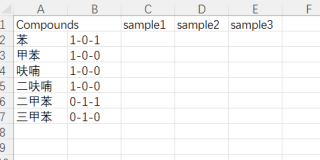
但是我的代码跑出来的结果却是
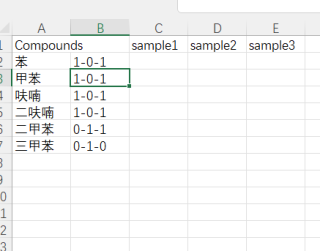
想了很久都想不出来原因,有人能指点一下吗?
import csv
import time
#创建字典,存放compounds与不同样品之间的关系
total_list = {}
#输出程序开头
print('*'*24)
print('Copyright 2021 Ke Yang\nVersion 1.0_Python\nkeyang@seu.edu.cn')
print('*'*24)
#生成表格头文件
head_name=['Compounds','']
head_name_count = int(input('输入需要处理的样品个数:'))
print('------------------------------------------------')
#创建初始列表
sample_info_1 = ['1']
for i_info in range(1,head_name_count):
sample_info_1.append('0')
#导入第一个表格数据,生成初始字典
loading_floder = input('输入所有表格所在文件夹地址:')
loading_name = input('输入第1个表格名(直接复制文件名,不复制.csv):')
head_name.append(loading_name)
with open(loading_floder + '\\' + loading_name + '.csv', newline='',encoding='utf-8-sig') as sample_list_1:
reader_1 = csv.reader(sample_list_1)
for sample_1 in reader_1:
str_sample_name_1 = ''.join(sample_1)
total_list[str_sample_name_1] = sample_info_1
print('------------------------------------------------')
for i_csv in range(1,head_name_count):
loading_name = input(f'输入第{i_csv+1}个表格名(直接复制文件名,不复制.csv):')
head_name.append(loading_name)
with open(loading_floder + '\\' + loading_name + '.csv', newline='',encoding='utf-8-sig') as sample_list:
reader = csv.reader(sample_list)
for sample_row in reader:
str_sample_name = ''.join(sample_row)
if str_sample_name in total_list:
total_list[str_sample_name][i_csv] = '1'
else:
#生成新的判断式
new_sample_info = []
for i_info in range(head_name_count):
new_sample_info.append('0')
new_sample_info[i_csv] = '1'
total_list[str_sample_name]=new_sample_info
print('------------------------------------------------')
time.sleep(0.5)
print('汇总完成!')
print('------------------------------------------------')
save_floder = input('输入希望保存汇总文件的文件夹地址:')
with open(save_floder + '\\' + 'total_compounds.csv','a', newline='',encoding='utf-8-sig') as total_list_writer:
writer = csv.writer(total_list_writer)
writer.writerow(head_name)
for compounds in total_list:
writer.writerow([compounds,'-'.join(total_list[compounds])])
print('文件已生成')
python赋值变量是浅拷贝,举个例子
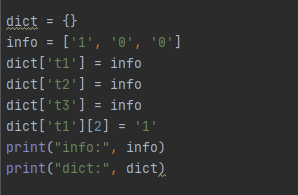

t1,t2,t3赋值变量info,修改t1,t2,t3里的值,info也会改变,所有值为info的地方都会变
理想状态的编号也没看到规律啊