python 爬取网页时出现多种错误
我想要爬取的是sensortower这个网站上的软件排行榜和软件信息,使用selenium,主要代码是下面这个图这样

(most Traceback recent ca1t Last)
File /users sunchubai/DownLoads/rank2.py Line 95,in<module>
rating anal.xpath(//*[@id app-profile-ratings"]/div[2]/div/div/span[1]/meta[2]·)[e].xpath( @content 一 一
List IndexErrOr: index 0utof Pange
常常报错的问题是下面图中的评分
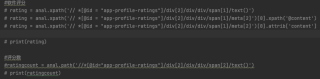
#软件评分
#rating anal.xpath(// *@id =“app-profile-ratings"]/div[2]/div/div/span[1]/text())
#rating anal.xpath(//*[@id 1=“app-profile-ratings"]/div[2]/div/div/span[1]/meta[2][e].xpath(dcontent)
#rating =anal.xpath(//*[@id=“app-profile-ratings"]/div[2]/div/div/span[1]/meta[2])[].attrib['content]
#print(rating
共评分数
热catingcount..anal.ath(./*l@d=app-profile.catings/diy.2l/div/div/spanl2]/textO).)
#print(ratingcount
在谷歌上搜索之后尝试了一些办法,但是这个代码也没有起到作用,还是依旧会报错。

try:
anal.xpath(//*[@id= Pating 一 app-profile-ratings"]/div[2]/div/div/span[1]/meta[2])[o].xpath(@content')
except IndexErrOr:
rating nuL7
目前已经出现的错误中最常出现的是这个

(most Traceback recent ca1t Last)
File /users sunchubai/DownLoads/rank2.py Line 95,in<module>
rating anal.xpath(//*[@id app-profile-ratings"]/div[2]/div/div/span[1]/meta[2]·)[e].xpath( @content 一 一
List IndexErrOr: index 0utof Pange
还请帮忙看看,我要怎么解决这个问题。 谢谢!
代码中anal.xpath(//*[@id= Pating 一 app-profile-ratings"]/div[2]/div/div/span[1]/meta[2])可能获取到为空列表,不能用[0]索引取值。
为演示代码,这里使用lxml库解析,试试这样:
s='''<div>
<span class ="stars">
<meta itemprop="worstRating" content="0">
<meta itemprop="ratingValue" data-bind="attr:{content:$data.rating}" content="3.93239"}></span>
<span class="stars five gold" data-bind="style:{width:data.rating*100/5+'%'}" style ="width: 78.6478%;"></span>'''
from lxml import etree
html=etree.HTML(s)
try:
ele= html.xpath("//div/span[1]/meta[2]")
print(ele)
rating=ele[0].attrib['content']
except:
rating=''
print(rating)
运行结果:
F:\2021\qa\ot2>t6
[<Element meta at 0x2e5c5d7a648>]
3.93239
可以加个判断或者捕获这个错误