爬取网页需要完整代码用两种方法
需要代码
页面数据接口这个,修改下page参数获取指定页的数据即可,不过接口返回的是html代码,具体内容需要用BeautifulSoup解析下
https://www.maigoo.com/brand/search/?catid=8961&page=1&ajax=1&subaction=resultlist&action=searchlist
题主要的代码如下,有帮助麻烦点下【采纳该答案】,谢谢~~有其他问题可以继续交流~
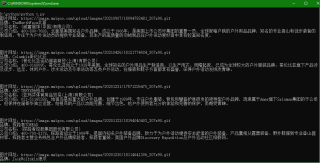
import requests
from bs4 import BeautifulSoup
for i in range(1,3):#采集1,2页数据
url="https://www.maigoo.com/brand/search/?catid=8961&page=%s&ajax=1&subaction=resultlist&action=searchlist"%i
html=requests.get(url).text
soup=BeautifulSoup(html,features="html.parser")
lis=soup.select('li')
for li in lis:
print('图片网址:'+li.select('img')[0].attrs['src'])
print('品牌:'+li.select('.info a.name')[0].text)
print('公司名称:'+li.select('.cbox')[0].text)
print('公司介绍:'+li.select('.rongyu')[0].text)
print('\n\n')
哈哈
哈哈哈,
你好直接
import requests
daima = requests.get('https://www.maigoo.com/brand/search/?catid=8961');
print('代码如下:')
print(daima)