python groupby问题,如何取出现过最多的人名和所有人的平均成绩
python的pandas dataframe问题
有一个dataframe类似这种
班级 姓名 跑步 跳高
1 张三 7.5 1.8
1 张三 7.8 2
2 王五 6.8 2.1
2 陈六 5.8 1.5
2 陈六 6 1.8
3 钱二 5.5 2
3 赵一 7.2 2.1
3 赵一 6 2.1
1 张三 7.8 1.9
1 李四 6.2 1.7
1 李四 7 2.2
2 周七 6.1 1.8
2 彭八 9 2.0
要筛选出每个班出现过最多的人名然后每班所有人的平均跑步成绩和跳高成绩
像这样
班级 姓名 跑步 跳高
1 张三 所有人平均 所有人平均
2 陈六
3 赵一
#x是dataframe
x.groupby(by='姓名').mean()
结果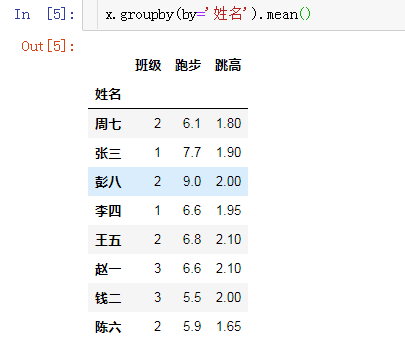
出现次数
x.groupby(by=['班级','姓名']).count()
输出: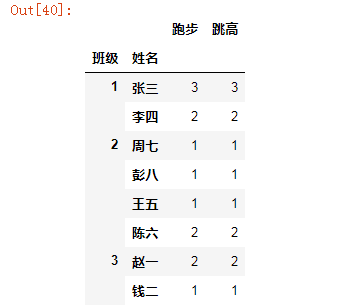
输出人名要麻烦一些
from scipy.stats import mode
x.groupby(by=['班级']).aggregate(mode)['姓名']
输出
df1 = df.groupby(['姓名']).mean()
df1['次数'] = df['姓名'].groupby(df['姓名']).count()
df1 = df1.sort_values(by='次数', ascending=False)
df1