在用VGG训练猫狗分类中,不用预训练权重,loss值一直保持在0.69附近,如何解决?
from torch import nn
from torchvision import models,datasets,transforms
import torch
import os
from torch.autograd import Variable
from torch.optim.lr_scheduler import *
data_dir = 'data'
data_transform = {
'train':transforms.Compose([transforms.Resize((150, 150)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225]),
transforms.RandomHorizontalFlip(p=0.5),#水平翻转
transforms.RandomRotation(50), # 随机旋转
transforms.RandomResizedCrop(150)
]),
'valid':transforms.Compose([transforms.Resize((150, 150)),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], [0.229,0.224,0.225])
])
}
image_datasets = {x:datasets.ImageFolder(root=os.path.join(data_dir, x), transform=data_transform[x])
for x in ['train','valid']
}
dataloader = {x:torch.utils.data.DataLoader(dataset=image_datasets[x], batch_size=30, shuffle=True, num_workers=4)
for x in ['train','valid']
}
x_example, y_example = next(iter(dataloader['train']))
example_classes = image_datasets['train'].classes
index_classes = image_datasets['train'].class_to_idx
model = models.vgg16(pretrained=False)
# 遍历模型中的所有模块
for m in model.modules():
# 如果当前模块是卷积层或者线性层
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_normal_(m.weight)
nn.init.constant_(m.bias, 0)
model.classifier = torch.nn.Sequential(
torch.nn.Linear(25088,512),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(512,512),
torch.nn.ReLU(),
torch.nn.Dropout(p=0.5),
torch.nn.Linear(512,2)
)
use_gpu = torch.cuda.is_available()
if use_gpu :
model = model.cuda()
loss_f = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.classifier.parameters(), lr=1e-5)
epochs = 99999
global_step = 0
best_acc = 0
best_epoch = 0
with open("loss2.txt", "w") as f:
for epoch in range(epochs):
print('----' * 10)
print('Epoch {}/{}'.format(epoch + 1, epochs))
for phase in ['train', 'valid']:
if phase == 'train':
print('Training...')
model.train(True)
else:
print('Validing...')
model.train(False)
running_loss = 0.0
running_corrects = 0
for batch, data in enumerate(dataloader[phase]):
#x为数据,y为标签
x, y = data
x, y = Variable(x.cuda()), Variable(y.cuda())
#得到30个输出预测
y_pred = model(x)
#pred为预测结果
_, pred = torch.max(y_pred.data, 1)
loss = loss_f(y_pred, y)
for per in y_pred.data:
print(per)
running_loss += loss.data
if phase == 'train':
global_step += 1
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_corrects += torch.sum(pred == y.data)
epoch_loss = running_loss * 30 / len(image_datasets[phase])
epoch_acc = 100 * running_corrects / len(image_datasets[phase])
print('{} Loss:{} ACC:{}'.format(phase, epoch_loss, epoch_acc))
if(phase == 'train'):
f.writelines([str(epoch), ',', str(epoch_loss.item()),',',str(epoch_acc.item()), ','])
if(phase == 'valid'):
f.writelines([str(epoch_acc.item()),',',str(epoch_loss.item()), ';'])
f.flush()
if epoch_acc.item() > best_acc:
torch.save(model, 'best3.pth')
best_acc = epoch_acc.item()
best_epoch = epoch
print('最好的正确率是epoch:', best_epoch+1, ' 正确率为:', best_acc)
print('最好的模型在epoch:', best_epoch)
torch.save(model, 'vggmodel2.pth')

提取码:gbuh
这里有一个比较好的参数设置,我之前用到过,可以自己对比一下不同,另外你的0.69也很巧合,与log(0.5)的值很接近,可以调查一下。我之前学习的代码,精度能达到0.99左右。
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms, models
data_dir = '../data' #DOWNLOAD DATA FOR THIS
train_transforms = transforms.Compose([transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
test_transforms = transforms.Compose([transforms.Resize(255),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
train_data = datasets.ImageFolder(data_dir + '/train', transform=train_transforms)
test_data = datasets.ImageFolder(data_dir + '/test', transform=test_transforms)
trainloader = torch.utils.data.DataLoader(train_data, batch_size=64, shuffle=True)
testloader = torch.utils.data.DataLoader(test_data, batch_size=64)
model = models.densenet121(pretrained=True)
print(model)
for param in model.parameters():
param.requires_grad = False
from collections import OrderedDict
classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(1024, 512)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(512,256)),
('relu2', nn.ReLU()),
('fc3', nn.Linear(256, 2)),
('output', nn.LogSoftmax(dim=1))
]))
model.classifier = classifier
# Use GPU if it's available
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = models.densenet121(pretrained=True)
# Freeze parameters so we don't backprop through them
for param in model.parameters():
param.requires_grad = False
model.classifier = nn.Sequential(nn.Linear(1024, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.1),
nn.Linear(256, 2),
nn.LogSoftmax(dim=1))
criterion = nn.NLLLoss()
# Only train the classifier parameters, feature parameters are frozen
optimizer = optim.Adam(model.classifier.parameters(), lr=0.003)
model.to(device);
traininglosses = []
testinglosses = []
testaccuracy = []
totalsteps = []
epochs = 1
steps = 0
running_loss = 0
print_every = 5
for epoch in range(epochs):
for inputs, labels in trainloader:
steps += 1
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
logps = model.forward(inputs)
loss = criterion(logps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device), labels.to(device)
logps = model.forward(inputs)
batch_loss = criterion(logps, labels)
test_loss += batch_loss.item()
# Calculate accuracy
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor)).item()
traininglosses.append(running_loss/print_every)
testinglosses.append(test_loss/len(testloader))
testaccuracy.append(accuracy/len(testloader))
totalsteps.append(steps)
print(f"Device {device}.."
f"Epoch {epoch+1}/{epochs}.. "
f"Step {steps}.. "
f"Train loss: {running_loss/print_every:.3f}.. "
f"Test loss: {test_loss/len(testloader):.3f}.. "
f"Test accuracy: {accuracy/len(testloader):.3f}")
running_loss = 0
model.train()
from matplotlib import pyplot as plt
plt.plot(totalsteps, traininglosses, label='Train Loss')
plt.plot(totalsteps, testinglosses, label='Test Loss')
plt.plot(totalsteps, testaccuracy, label='Test Accuracy')
plt.legend()
plt.grid()
plt.show()
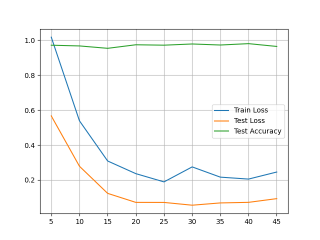
如果有用,请采纳,谢谢!
1.评估下训练集样本类别是否均匀,类别不均匀可以通过离线数据增强扩充样本,或者在计算损失的时候对类别样本数少的那一类增加权重
2.学习率使用warmup策略
3.优化器尝试下sgd
4.换resnet系列主干网络
5.评估出错的情况,进行样本扩充或者对应的数据增强