python使用xpath爬取网络数据报表结果为空
采集公司内部提供的数据报表,在xpath输出的过程中结果为[]
无返爬机制 求解决
url='https://fr.oppein.com:9001/op/decision/view/report?viewlet=/%E5%A4%A9%E6%B4%A5%E5%9F%BA%E5%9C%B0/%E5%A4%A9%E6%B4%A5%E7%94%9F%E4%BA%A7%E8%AE%A1%E5%88%92%E9%87%87%E8%B4%AD%E9%83%A8/%E3%80%90XMES%E3%80%91%E5%A4%A9%E6%B4%A5%E5%AE%B6%E5%85%B7%E5%8E%82%E6%9F%9C%E8%BA%AB%E7%94%9F%E4%BA%A7%E7%BA%BF%E5%8C%85%E8%A3%85%E5%AE%8C%E6%88%90%E6%83%85%E5%86%B5.cpt'
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}
get = requests.get(url=url,headers=headers).text
html_new = get.replace('<!--', '"').replace('-->', '"')#正则表达式 注释性切换字符
selector = etree.HTML(html_new) # 将源码转换为xpath可以识别的TML格式
print(selector.xpath('//title/text()'))#标题采集title
wz=selector.xpath('/html/body/div[1]/div/div/div/div/div/table/tbody/tr[9]/td[1]')
wz2=selector.xpath('//*[@id="A9-0-223416"]')
print(wz)
print(wz2)
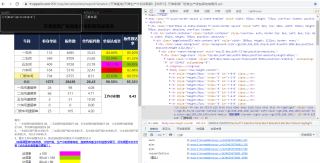
该页面数据在XHR中找,构建一下headers和params,使用如下方式获json数据,然后从中解析即可:
response = requests.get('https://fr.oppein.com:9001/op/decision/view/report', headers=headers, params=params)
js=response.json()
print(js)
它这个门板车间的 id 是变化的,每次请求不一样,所以没选中元素就为空了
你用requests发送请求的要用开发者工具的network的doc分析网页,如图

你截图的分析网页是selenium自动化用的,两者是有区别的