爬虫只能运行第一页,不能爬取后续页码
想爬取美女图片,网址:http://www.tu11.com/xingganmeinvxiezhen/list_1_1.html
编写了如下爬虫:
import requests
from bs4 import BeautifulSoup
def get_1_page(url):
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"}
response = requests.get(url,headers=headers).text
return response
def parse_1_page(html):
soup=BeautifulSoup(html,'lxml')
for a in soup.find_all(class_='col-xs-1-5'):
print(a.img['src'])
for i in range(1,10):
url='http://www.tu11.com/xingganmeinvxiezhen/list_1_'+str(i)+'.html'
html=get_1_page(url)
parse_1_page(html)
但是只能爬取第一页,之后就报错误: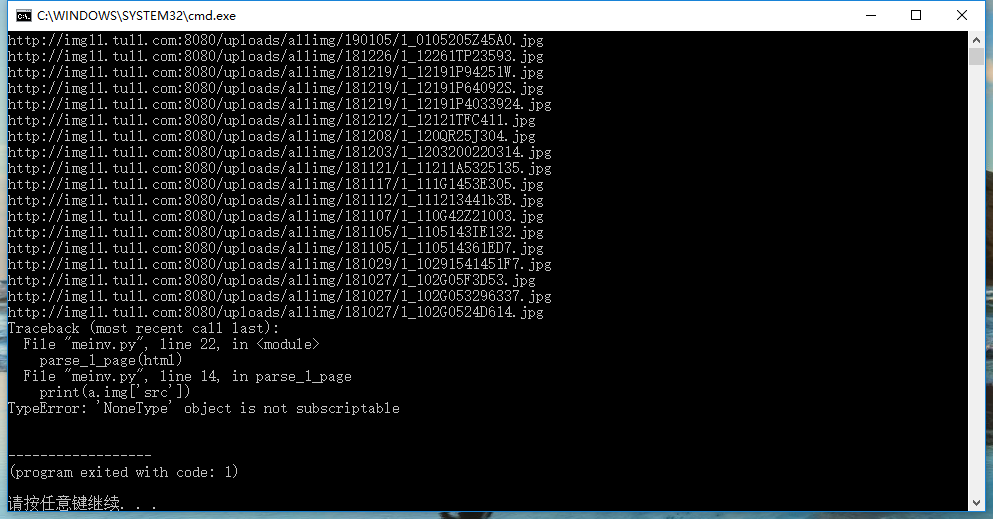
求大神看看
https