mysql8.0 使用mysql.connector模块, 连接不了数据库,不可用,存储失败,找不到原因
使用 pymysql 模块正常 读取和存储
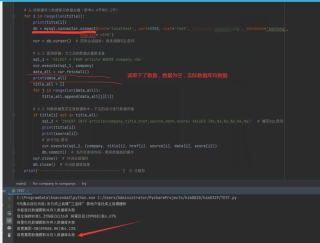
#! /usr/bin/env python
#-*- encoding: utf-8 -*-
import requests
import re
import pymysql
import time
import mysql.connector # mysql 8.0 连接模块
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
def baidu(company):
# 1.获取网页源代码(参考2.3、3.1、3.4节)
url = 'https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&ie=utf-8&word=' + company # 其中设置rtt=4则为按时间排序,如果rtt=1则为按焦点排序
res = requests.get(url, headers=headers, timeout=10).text
# 2.编写正则提炼内容(参考3.1节)
p_href = '<h3 class="news-title_1YtI1">.*?<a href="(.*?)"'
p_title = '<a href=.*?class="news-title-font_1xS-F".*?aria-label="(.*?)".*?</a>'
p_info = '<span class="c-color-gray c-font-normal c-gap-right".*?>(.*?)</span>'
p_date = '<span class="c-color-gray2 c-font-normal".*?>(.*?)</span>'
href = re.findall(p_href, res, re.S)
title = re.findall(p_title, res, re.S)
info = re.findall(p_info, res, re.S)
source = info
date = re.findall(p_date, res, re.S)
# 3.数据清洗(参考3.1节)
for i in range(len(title)):
title[i] = title[i].strip()
title[i] = re.sub('标题:', '', title[i])
score = []
# 6.将数据存入数据库及数据去重(参考4.4节和5.1节)
for i in range(len(title)):
print(title[i])
db = mysql.connector.connect(host='localhost', port=3308, user='root', password='x', database='pachong',
charset='utf8')
cur = db.cursor() # 获取会话指针,用来调用SQL语句
# 6.1 查询数据,为之后的数据去重做准备
sql_1 = 'SELECT * FROM article WHERE company =%s'
cur.execute(sql_1, company)
data_all = cur.fetchall()
print(data_all)
title_all = []
for j in range(len(data_all)):
title_all.append(data_all[j][1])
# 6.2 判断数据是否在原数据库中,不在的话才进行数据存储
if title[i] not in title_all:
sql_2 = 'INSERT INTO article(company,title,href,source,date,score) VALUES (%s,%s,%s,%s,%s,%s)' # 编写SQL语句
print(title[i])
print(source[i])
# 执行SQL语句
cur.execute(sql_2, (company, title[i], href[i], source[i], date[i], score[i]))
db.commit() # 当改变表结构后,更新数据表的操作
cur.close() # 关闭会话指针
db.close() # 关闭数据库链接
print('------------------------------------') # 分割符
def main():
# 7.批量爬取多家公司(参考3.2节)
companys = ['华能信托', '阿里巴巴', '百度集团']
for company in companys:
try:
baidu(company)
print(company + '数据爬取并存入数据库成功')
except:
print(company + '数据爬取并存入数据库失败')
main()
sql语句模板中的参数填充符是 %s 而不是 ‘%s’ ,且多个参数需要用元祖存放,单个参数可直接传递,将你的模板语句做如下改动即可
sql_1 = "SELECT * FROM article WHERE company ='%s'"
sql_2 ="'INSERT INTO article(company,title,href,source,date,score) VALUES ('%s','%s','%s','%s','%s','%s')" # 编写SQL语句
有帮助请采纳,有问题继续交流,你的采纳是对我回答的最大的肯定和动力