python for循环 只爬取最后一页的内容
本来想要随便爬几页动漫的标题和标签,结果连翻页都搞不定
希望各位能指点一下,感谢
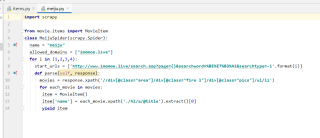
代码这样修改一下,应该可以,代码中为了测试将Item写成了一个类,你可以去掉它,用导入语句:
import scrapy
class MovieItem(scrapy.Item):
name=scrapy.Field()
class MeijuSpider(scrapy.Spider):
name="meiju"
allowed_domains=['imomoe.live']
def start_requests(self):
starts_urls = [
f'http://www.imomoe.live/search.asp?page={i}&searchword=%BE%E7%B3%A1&searchtype=-1' for i in range(1, 5)]
#url = "'http://www.imomoe.live/search.asp?page=1&searchword=%BE%E7%B3%A1&searchtype=-1'"
headers = {'USER_AGENT': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/91.0.4472.106 Safari/537.36 '}
for url in starts_urls:
yield scrapy.Request(url, headers=headers, callback=self.parse)
def parse(self,response):
movies = response.xpath(
'//div[@class="area"]/div[@class="fire l"]/div[@class="pics"]/ul/li')
item=MovieItem()
for each_movie in movies:
print(each_movie)
item['name']=each_movie.xpath('./h2/a/@title').extract()[0]
yield item
你print(i)看看程序执行了几次循环