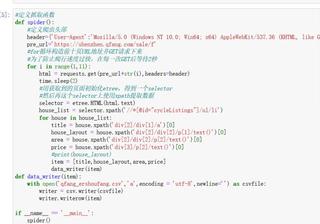
友友们 这个代码哪里错了 出不来结果
#定义抓取函数
def spider():
#定义爬虫头部
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'}
pre_url='
#for循环构造前十页URL地址并GET请求下来
#为了防止爬行速度过快,在每一次GET后等待2秒
for i in range(1,11):
html = requests.get(pre_url+str(i),headers=header)
time.sleep(2)
#用获取到的页面初始化etree,得到一个selector
#然后再这个selector上使用xpath提取数据
selector = etree.HTML(html.text)
house_list = selector.xpath('//*[@id="cycleListings"]/ul/li')
for house in house_list:
title = house.xpath('div[2]/div[1]/a')[0]
house_layout = house.xpath('div[2]/div[2]/p[1]/text()')[0]
area = house.xpath('div[2]/div[2]/p[2]/text()')[0]
price = house.xpath('div[3]/p[2]/text()')[0]
#print(house_layout)
item = [title,house_layout,area,price]
data_writer(item)
def data_writer(item):
with open('qfang_ershoufang.csv','a',encoding = 'utf-8',newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(item)
if name == 'main':
spider()