python入门爬虫,爬不出来图片。
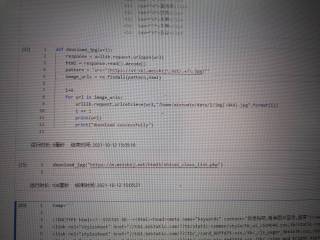
为什么爬不了来图片呀,爬不出来。
def download_jpg(url):
response = urllib.request.urlopen(url)
html = response.read().decode()
pattern = 'src="(https://st-cn\.meishij\.net/.+?\.jpg)"'
image_urls = re.findall(pattern,html)
i=0
for url in image_urls:
urllib.request.urlretrieve(url,"/home/aistudio/data/1/img{:04d}.jpg".format(i))
i += 1
print(url)
print("download successfully")
在爬虫过程中,最好把请求头添加上
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import re,requests
from urllib.request import urlretrieve
url = 'https://www.meishij.net/zuofa/zhuduji_7.html'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36",
"Refer":'https://www.meishij.net/',
"Host":"www.meishij.net",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3",
}
def download_jpg(url):
html = requests.get(url,headers=headers).content.decode('utf-8')
pattern = 'src="(https://st-cn\.meishij\.net/.+?\.jpg)"'
image_urls = re.findall(pattern, html)
count = 0
for image_url in image_urls:
print(image_url)
name = image_url.rsplit('/', 1)[1]
urlretrieve(image_url, name)
# urlretrieve(image_url, '/home/aistudio/data/1/img{}'.format(name))
count += 1
print("download successfully")
print(count)
if __name__ == '__main__':
url = 'https://www.meishij.net/zuofa/zhuduji_7.html'
download_jpg(url)
错误信息贴一下