关于#python#的问题:请问怎么用beautifulsoup来解析爬取书名之类的信息呢
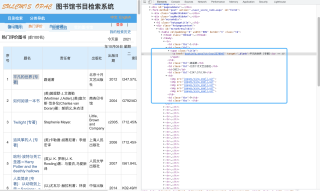
请问怎么用beautifulsoup来解析爬取书名之类的信息呢?我总是用find ()和find_all方法却爬不出东西太绝望了!
你把完整的代码用代码段以文本的形式发一下看看

你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
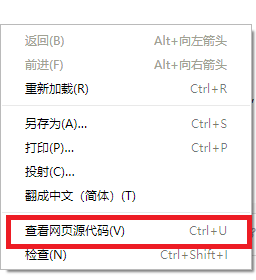
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
请看官方文档/教程
我一般会按照这个逻辑去找到信息
首先用点操作符或者 s=find(id=xxx) 先尽可能缩小搜索范围,然后再在 s 里慢慢找到需要的信息。。。