print(xx.abbr.text),输出的结果是> ,再print(xx.abbr.text=="> "),结果却是false,这是何解?

好像我说的还不够明白。。。这样讲吧,我用python写了一段代码用于判断图中那个abbr的标签里的内容。我先print(abbr.text),输出的结果是> ,即一个大于号加一个空格;
然后我再print(abbr.text=="> "),结果却是false,这是何解?我明明只是把上面的结果复制粘贴了而已。
我右键那段代码选择“edit as HTML",然后把内容截图如下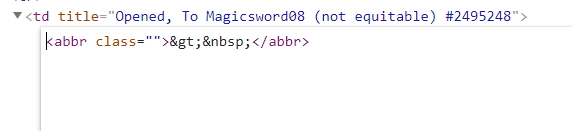
然后搜索那个gt和nbsp,感觉是这两个字符转义造成的问题,但不知道该如何解决。
另外,这里有一个测试地址,可以试试https://barter.vg/u/3cc3/o/ 找随便一个大于号 (>) 审查元素,出现类似于我上面的截图,然后print看看结果。
马勒戈壁这该死的问题,搞了一整天,终于闹明白了!!!!
真的是这个转码问题!!!详情请见https://blog.csdn.net/codingforhaifeng/article/details/80615008

说明一下,xxxx.abbr.text是直接从html提取来的内容,虽然输出结果是> ,实际上是2个转义符,你在python的输出结果是看不到区别的,坑爹啊!!!必须要用html的unescape来反转义!
结帖!!!!!
==用来比较值是否相同,你先确定abbr.text的值是否真的是“> ",可以先a = abbr.text ,看看a的值是否是"> ",