【python】【文字识别】百度文档识别返回的结果,整理为dataframe表格
一、背景
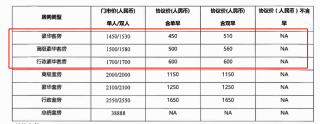
pdf文档中有一个表格(请见附一),已获得百度文档识别返回的结果(请见附二,节选红框所示的三行)。
二、目标
将返回的结果整理成python_dataframe表格
三、请帮助
如何使用python实现?谢谢
附一:原始表格
附二:初步识别代码(json)
a = [
{
"words_location": {"top": 382, "left": 124, "width": 52, "height": 12},
"word": "豪华客房",
},
{
"words_location": {"top": 383, "left": 280, "width": 59, "height": 11},
"word": "14501530",
},
{
"words_location": {"top": 383, "left": 425, "width": 23, "height": 10},
"word": "450",
},
{
"words_location": {"top": 383, "left": 553, "width": 28, "height": 11},
"word": "510",
},
{
"words_location": {"top": 383, "left": 689, "width": 25, "height": 10},
"word": "NA ",
},
{
"words_location": {"top": 412, "left": 113, "width": 76, "height": 13},
"word": "高级豪华客房",
},
{
"words_location": {"top": 414, "left": 277, "width": 61, "height": 11},
"word": "5001580",
},
{
"words_location": {"top": 413, "left": 424, "width": 23, "height": 11},
"word": "500",
},
{
"words_location": {"top": 413, "left": 554, "width": 26, "height": 11},
"word": "560",
},
{
"words_location": {"top": 413, "left": 690, "width": 22, "height": 10},
"word": "NA ",
},
{
"words_location": {"top": 442, "left": 111, "width": 76, "height": 12},
"word": "行攻豪华客房",
},
{
"words_location": {"top": 444, "left": 278, "width": 60, "height": 12},
"word": "1700/1700",
},
{
"words_location": {"top": 444, "left": 424, "width": 25, "height": 10},
"word": "600",
},
{
"words_location": {"top": 444, "left": 554, "width": 27, "height": 10},
"word": "600",
},
{
"words_location": {"top": 444, "left": 689, "width": 22, "height": 10},
"word": "NA ",
},
]
import pprint
import pandas as pd
df=pd.DataFrame(columns=['B','C','D','E'])
dic = [
{
"words_location": {"top": 382, "left": 124, "width": 52, "height": 12},
"word": "豪华客房",
},
{
"words_location": {"top": 383, "left": 280, "width": 59, "height": 11},
"word": "14501530",
},
{
"words_location": {"top": 383, "left": 425, "width": 23, "height": 10},
"word": "450",
},
{
"words_location": {"top": 383, "left": 553, "width": 28, "height": 11},
"word": "510",
},
{
"words_location": {"top": 383, "left": 689, "width": 25, "height": 10},
"word": "NA ",
},
{
"words_location": {"top": 412, "left": 113, "width": 76, "height": 13},
"word": "高级豪华客房",
},
{
"words_location": {"top": 414, "left": 277, "width": 61, "height": 11},
"word": "5001580",
},
{
"words_location": {"top": 413, "left": 424, "width": 23, "height": 11},
"word": "500",
},
{
"words_location": {"top": 413, "left": 554, "width": 26, "height": 11},
"word": "560",
},
{
"words_location": {"top": 413, "left": 690, "width": 22, "height": 10},
"word": "NA ",
},
{
"words_location": {"top": 442, "left": 111, "width": 76, "height": 12},
"word": "行攻豪华客房",
},
{
"words_location": {"top": 444, "left": 278, "width": 60, "height": 12},
"word": "1700/1700",
},
{
"words_location": {"top": 444, "left": 424, "width": 25, "height": 10},
"word": "600",
},
{
"words_location": {"top": 444, "left": 554, "width": 27, "height": 10},
"word": "600",
},
{
"words_location": {"top": 444, "left": 689, "width": 22, "height": 10},
"word": "NA ",
},
]
k=0
for i in range(len(dic)//5):
a=dic[5*k+0]["word"]
b=dic[5*k+1]['word']
c=dic[5*k+2]['word']
d=dic[5*k+3]['word']
e = dic[5 * k +4]['word']
df.loc[a]=[b,c,d,e]
k+=1
pprint.pprint(df)
识别结果返回 json 也太抽象了,应该有直接返回 Excel 的选项
Python有个 json 库,说不定你可以用到。