scrapy 请求chrome控制台抓取到的请求地址,但是报404,地址直接在浏览器输入也是报404
chrome控制台看到的请求地址
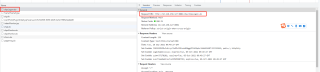
请求头如下
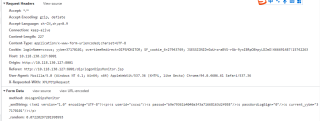
编写的spider如下:
from kemai.items import KemaiItem2
import logging
from kemai.items import a
from scrapy.downloadermiddlewares.cookies import CookiesMiddleware
class KemaispiderSpider(scrapy.Spider):
name = 'kemaispideryibao'
allowed_domains = ["10.118.130.127:8001"]
#start_urls = [constant.getHostUrl()]
#pagestart=0
hosturl="http://10.118.130.127:8001/"
headers = {
'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8',
'Host': '10.118.130.127:8001',
'Referer':'http://10.118.130.127:8001/dip/logonDipsMonitor.jsp',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36',
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN, zh;q = 0.9',
'Connection': 'keep-alive',
'Origin': 'http://10.118.130.127:8001',
'Cookie': 'loginName = cxcwz;yybm = 37170101; overtimeRedireect=DIPSMONITOR; SF_cookie_6=27943769; JSESSIONID=pEgrYU2R6JiKYZInaouDfkuXkhlJTvjQ!466691487!15742263',
'X-Requested-With': 'XMLHttpRequest'
}
# searchParam = {"gridSessionID":"53880640_b4fd_4d02_ab79_43b241cff015","page":"1","pageSize":"25","updateBeginRowIndex":"0","updateRows":"[]"}
def start_requests(self):
yield scrapy.Request("http://10.118.130.127:8001/dip/logonDipsMonitor.jsp", callback=self.login)
def login(self,response):
yield scrapy.Request(
url="http://10.118.130.127:8001/dip/dipsLogon.do",
body=json.dumps({"method": "doLogonDipsMonitor", "_xmlString": "<?xml version=\"1.0\" encoding=\"UTF-8\"?><p><s userid=\"cxcwz\"/><s passwd=\"b9e79361b4040a3f3a71668163d2f058\"/><s passWordLogSign=\"0\"/><s current_yybm=\"37170101\"/></p>", "_random": "0.015842269101861817"}),
dont_filter=True,
headers=self.headers,
callback=self.parse)
def parse(self, response):
print()
在pycharm中的执行结果如下:
2021-09-28 17:50:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2021-09-28 17:50:32 [scrapy.core.engine] DEBUG: Crawled (200) <GET http://10.118.130.127:8001/dip/logonDipsMonitor.jsp> (referer: None)
2021-09-28 17:50:34 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://10.118.130.127:8001/dip/dipsLogon.do> (failed 1 times): 404 Not Found
2021-09-28 17:50:38 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET http://10.118.130.127:8001/dip/dipsLogon.do> (failed 2 times): 404 Not Found
2021-09-28 17:50:42 [scrapy.downloadermiddlewares.retry] ERROR: Gave up retrying <GET http://10.118.130.127:8001/dip/dipsLogon.do> (failed 3 times): 404 Not Found
2021-09-28 17:50:42 [scrapy.core.engine] DEBUG: Crawled (404) <GET http://10.118.130.127:8001/dip/dipsLogon.do> (referer: http://10.118.130.127:8001/dip/logonDipsMonitor.jsp)
2021-09-28 17:50:42 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <404 http://10.118.130.127:8001/dip/dipsLogon.do>: HTTP status code is not handled or not allowed
404就是请求不到资源,路径问题,看你的报错呀 控制台里面是GET请求,但是浏览器里面是POST,这两个响应不同也就找不到路径了,如果不是这个问题那你就再仔细看看路径吧
404说明地址错了,仔细看看是不是地址那个位置少了什么