如何利用python提取Excel中长文本中特定字符后的数据
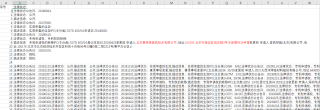
比如提取这两个位置的数据
使用pandas配合字符串切片拼接可以获取需要的数据(标点符号要一致)。
import pandas as pd
df=pd.read_excel('t929.xlsx')
line=df.loc[0,'法律状态'].split('\n')[8]#获取要处理的行数据
res=line[line.index('申请人:'):line.index('司')+1]+' '+line[line.index('地址:'):line.index('变更后')]#字符串切片分割和拼接。
print(res)
如有帮助,请点采纳。
你要提取什么特定字符,可以用正则表达式
参考代码如下:(如有帮助,望采纳!谢谢! 点击我这个回答右上方的【采纳】按钮)
import re
s = '描述信息:专利申请权的转移IPC(主分类)C07D403/04:登记生效日:20190423变更前 申请人:北京赛林泰医药技术有限公司,地址:100195北京市海淀区闵庄路3号玉泉慧谷16号楼变更后申请人:首药控股(北京)'
a,b = re.findall(r'申请人:(.+?),地址:(.+?)变更后申请人',s)[0]
print(a)
print(b)