用Python进行一系列的数据分析问题
已经拥有了数据如下所示:
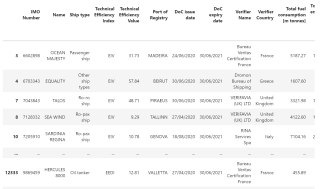
需要用Python做到如下数据处理:
想比较 EEDI 和 EIV 值的分布。我们使用 matplotlib boxplot 绘制两个并排的 boxplot,如下所示。我们可以在技术效率值中看到许多异常值。让我们使用 IQR 方法去除这些异常值。
IQR 方法:四分位距 (IQR) 计算为数据的第 75 个和第 25 个百分位数之间的差异。 IQR 方法将值高于 25% 或高于 75% 的值的 1.5 倍视为异常值。
对于每个数据帧 df_eedi 和 df_eiv,计算技术效率值的下限和上限。下限为 25% 以下的 IQR 的 1.5 倍,而上限为 75% 以上的 IQR 的 1.5 倍。
从 df_eedi 和 df_eiv 中删除技术效率值小于下限且大于上限的数据点。
编写代码绘制箱线图以比较两个指标下的技术效率值。最终的可视化必须遵循前面显示的箱线图中的规范,例如,具有共同 Y 轴的两个相邻的箱线图。
为技术效率、燃料消耗、二氧化碳排放、每英里燃料消耗、每英里二氧化碳排放之间的每个数据子集生成以下五个变量的双变量 Pearson 相关矩阵。
为不同类型船舶的 EEDI 索引数据生成技术效率值的箱线图。此箱线图包含 Y 轴上的技术效率值和 X 轴上的船舶类型。
想请教一下具体的操作方法,如有需要可以将我的数据文档和Python文档提供出来
数据点中的异常值处理,可参考如下方法:
这个首先获取两个列数据中的四分位差IQR=Q3-Q1,
a,b=df['device'].quantile([0.25,0.75])
IQR=b-a
获取到IQR,
然后使用语句:
df=df[(df['device']>a-1.5IQR) & (df['device']<b+1.5IQR)]
print(df)
剔除掉异常数据。
如有帮助请采纳。