python bs4爬虫问题,始终无法查找到部分要素,求各位解答
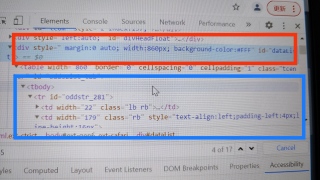
用bs4解析,可以查到图中红色圈中的div标签。
find、select等各种方法用完了都无法找到蓝色圈中的tr、td标签,不知道什么原因,是否与div中的style auto有关,应该如何爬取下面的tr、td标签。
你是用 requests 和 BeautifulSoup爬取网页的吗?
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
在页面上点击右键,右键菜单中选 "查看网页源代码"。
这样看到的才是网页的静态源代码。
如果这个网页的静态源代码中有你需要爬取的内容,就说明该页面没有动态内容,可以用requests爬取。
否则就说明该页面的内容是动态更新的,要用selenium 来爬取.
如有帮助,望采纳!谢谢! 点击我这个回答右上方的【采纳】按钮
可尝试导入 pandas,使用pd.read_html()去获取网页中表格看看。通过动态渲染出的数据无法通过requests.get方法获取,你可以将response.text保存到本地查看一下有无table标签内容,如无则是动态加载的数据,需要用selenium去获取。
你要确定自己爬取的是动态数据还是静态,动态数据大多通过Ajax和js生成的,你无法从网页中获取到它的数据信息。
这个table可能是前端框架动态渲染出来的,如果直接获取HTML进行解析的话,那么根本不会渲染处理,更别说定位了
这个使用应该用selenium 或者 playwright,等元素渲染出来之后再进行获取
如果帮助,还请点个【采纳】