Java银行回单图片文字识别
不要云服务,百度,阿里,腾讯之类的,项目是内网,云私有化又太贵
我写了一个调用Tesseract的方法,但是有个问题,这个在图片上没有表格时,识别度很高 但是有表格识别度就不行了
示例:无表格

结果
有表格
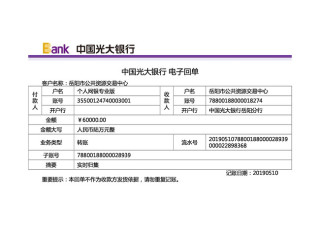
结果
相差太大惨不忍睹,
我Tesseract的语言包是用得中文的 21年9月官网最新的
求资深哥指点一下或者还有别的解决方案,有偿答问,只要能解决就好,
图片类型是银行回单,不要云,内网使用
先去除表格的线条:
遍历图像像素每一行,去除表格横线
遍历图像像素每一列,去除表格竖线
如何去除横线竖线:循环遍历一遍像素,连续超过N个像素颜色非背景色且颜色相同,则认为是一条线,替换成白色
提供一个思路,如果表格的边的颜色和文字相差比较大,就是有办法区分文字的点和边的点;
可以再读入图片对象后,再转换一下,判断是文字的点,重新赋值为黑色;判断为表格边的点赋值为白色;
做完转换后,再识别。
一个是线条影响,一个是图片大小、像素导致的,还有就是扫描版图片很多噪声
你可以多种方式试一下,看看哪个效果比较好。
比如,灰度处理后的图片再用ocr读,或者边缘强化,锐化、二值化等操作。Java应该也有相关函数的