数据库批量导入多个txt文件,数据缺失值处理 及日志文件生成
读入到某一条数据时“12345 , ,567989”的形式下无法读入, 缺失值如何填零值处理?
读入过程中生成日志文件,显示读到那一条出错并停止
设计表的时候,除了id字段,其他字段都不要勾选

这是插入空字符串的情况
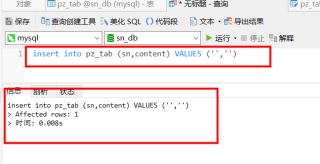
这是插入空值的情况
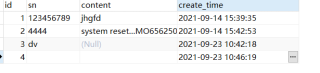
数据库的表该字段可以设置default 0
import os
import re
import MySQLdb
import chardet
import pandas as pd
from configs import mysql_DB # 填写配置文件
import logging
# 加日志,保存错误信息
root_logger = logging.getLogger()
root_logger.setLevel(logging.ERROR)
handler = logging.FileHandler('new.log', 'a', 'utf-8')
handler.setFormatter(logging.Formatter('%(pathname)s[line:%(lineno)d] - %(levelname)s: %(message)s'))
root_logger.addHandler(handler)
def insert2DB2(rootPath="Source/") -> int:
db = MySQLdb.connect(host=mysql_DB['HOST'], user=mysql_DB['USER'], passwd=mysql_DB['PASSWD'], db=mysql_DB['DB'],
charset=mysql_DB['CHARSET'], port=mysql_DB['PORT'])
sql = 'insert into student(sname, age, classname, averageScore) values(%s,%s,%s,%s)'
totalChangeNum = 0
with db.cursor() as cursor:
for root, dirs, files in os.walk(rootPath):
for fn in files:
if not fn.endswith(".txt"):
continue
file_path = os.path.join(root, fn)
# 如果确定文件的编码都是一样的,下面的with可以不要
with open(file_path, 'rb') as f: # 二进制打开文件
r = f.read()
f_charinfo = chardet.detect(r) # 获取编码
# dataframe = pd.read_csv(file_path, sep=',', encoding=f_charinfo['encoding']) # 这个只能处理单一的分隔符
dataframe = pd.read_csv(file_path, sep=r'\W', encoding=f_charinfo['encoding'],
engine='python') # 可以处理各种非字母数字符号做分割符的情况
try:
num = cursor.executemany(sql, dataframe.values.tolist()) # 本次修改的次数
totalChangeNum += num
db.commit()
except Exception as e: # 发生错误时回滚
if dataframe.isnull().values.any(): # 判断是否有nan值
emptyList = dataframe[dataframe.isna().any(axis=1)].values.tolist()
errorInfo = '%s happen at file %s: %s' % (str(e), file_path, str(emptyList))
else:
errorInfo = '%s happen at file %s' % (str(e), file_path)
print(errorInfo)
logging.error(errorInfo)
db.rollback()
return totalChangeNum
你这2个逗号中间,不是有个空格吗? 肯定不是数字,也许是 ... NULL。
所以可以导入时,指定 null_value