爬虫使用beautiful soup4时遇到Your browse does not support frame!,新手求解决
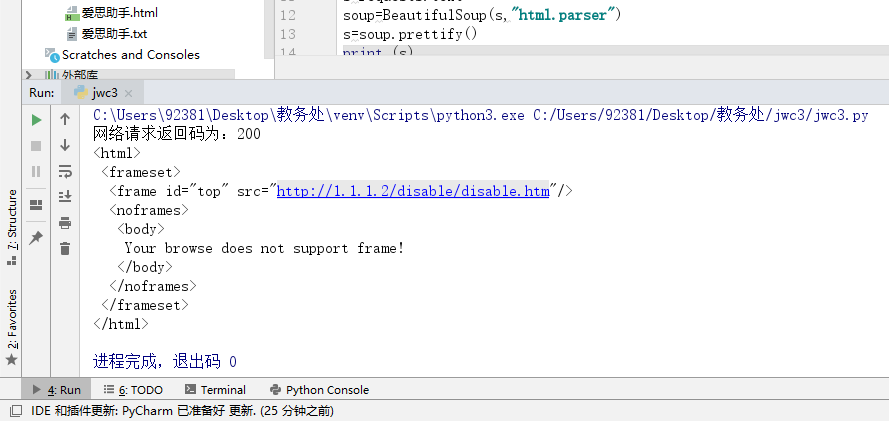
最近在学习python爬虫,试着爬取一些网站信息后,想要爬取学校教务处网站,学校查成绩的入口只有校园网可以进,但是之前有人做出来了爬虫可以爬取教务处成绩,我也想做出来。网站在IE和Chrome浏览器下都显示此内容无法在框架在一个框架中,新窗口打开也不行,查网上一些资料说用beautiful soup4解析网站即可,但是依然不行,出现了上面那句英文。scr的连接是http://1.1.1.2/disable/disable.htm有没有大神指点下。。。。。
代码如下:
import requests;
import logging;
from bs4 import BeautifulSoup;
import os;
url = "http://jwcweb3.wit.edu.cn";
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36"};
logging.captureWarnings(True);
requests = requests.get(url=url,verify=False,data=header);
print("网络请求返回码为:%d"%requests.status_code);
requests.encoding=requests.apparent_encoding
s=requests.text
soup=BeautifulSoup(s,"html.parser")
s=soup.prettify()
print (s)