Python爬虫 这里的第一个<i>标签为什么用Find_all查找不到,自动跳过了啊
html='''
<dd>
<i class="board-index board-index-1">1</i> #为什么这里的i标签回被find_all直接跳过?
<a href="/films/1200486" title="我不是药神" class="image-link" data-act="boarditem-click" data-val="{movieId:1200486}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="https://p0.meituan.net/movie/414176cfa3fea8bed9b579e9f42766b9686649.jpg@160w_220h_1e_1c" alt="我不是药神" class="board-img" />
</a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/1200486" title="我不是药神" data-act="boarditem-click" data-val="{movieId:1200486}">我不是药神</a></p>
<p class="star">
主演:徐峥,周一围,王传君
</p>
<p class="releasetime">上映时间:2018-07-05</p> </div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.</i><i class="fraction">6</i></p>
</div>
</div>
</div>
</dd>
'''
soup=BeautifulSoup(html,"html.parser")
for tag in soup.find('dd').children:
if isinstance(tag,bs4.element.Tag):
rank=tag.find_all('i')
print(rank)
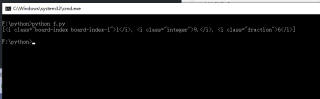
结果:[<i class="integer">9.</i>, <i class="fraction">6</i>]
第一个i是dd的子元素,遍历的时候tag就包含i。i再找i,html结构中并没有i嵌入i的结构,所以无法找到。直接获取dd节点find_all下面的i节点就行
有帮助麻烦点个采纳【本回答右上角】,谢谢~~
soup=BeautifulSoup(html,"html.parser")
rank=soup.find('dd').find_all('i')
print(rank)
看这个语法
因为if False;