关联分析 apriori报错keyerror
风变编程讲关联分析内容时,在风变的环境下运行不报错,但是在本地visual studio code中运行,报错如下:
PS D:\python> & C:/Users/raja/AppData/Local/Programs/Python/Python38/python.exe d:/python/apriori.py
Traceback (most recent call last):
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\indexes\base.py", line 3361, in get_loc
return self._engine.get_loc(casted_key)
File "pandas\_libs\index.pyx", line 76, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\index.pyx", line 108, in pandas._libs.index.IndexEngine.get_loc
File "pandas\_libs\hashtable_class_helper.pxi", line 5198, in pandas._libs.hashtable.PyObjectHashTable.get_item
File "pandas\_libs\hashtable_class_helper.pxi", line 5206, in pandas._libs.hashtable.PyObjectHashTable.get_item
KeyError: '文章类别'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "d:/python/apriori.py", line 43, in <module>
results = apriori(adjusted_data['文章类别'],min_support=0.1, min_confidence=0.3)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\series.py", line 942, in __getitem__
return self._get_value(key)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\series.py", line 1051, in _get_value
loc = self.index.get_loc(label)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\indexes\multi.py", line 2922, in get_loc
loc = self._get_level_indexer(key, level=0)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\indexes\multi.py", line 3204, in _get_level_indexer
idx = self._get_loc_single_level_index(level_index, key)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\indexes\multi.py", line 2855, in _get_loc_single_level_index
return level_index.get_loc(key)
File "C:\Users\raja\AppData\Local\Programs\Python\Python38\lib\site-packages\pandas\core\indexes\base.py", line 3363, in get_loc
raise KeyError(key) from err
KeyError: '文章类别'
代码如下:
import pandas as pd
from apyori import apriori
# 以 gbk 的编码模式读取并查看【公众号用户访问数据.csv】数据
user_data = pd.read_csv('C:\\Users\\raja\\Desktop\\test\\公众号用户访问数据.csv',encoding='gbk')
#********提取列数据************
# 提取列数据('用户编号', '文章类别','访问日期'),并进行赋值
analysis_data = user_data[['用户编号', '文章类别', '访问日期']]
#********数据去重************
# 查看提取数据后的重复数据
# analysis_data[analysis_data.duplicated()]
# 去除重复数据
analysis_data = analysis_data.drop_duplicates()
#********批量转换数据类型,由字符串转为列表,这样才能在聚合之后所有项目都变为单个列表元素************
# 定义函数,将数据类型转换成列表
def conversion_data(category):
# 判断文章类别是否已经转成了列表格式
if str(category)[0] == '[':
# 直接返回文章类别
return category
# 返回转成列表格式后的文章类别
return [category]
# 获取'文章类别'列,调用 agg() 方法
analysis_data['文章类别'] = analysis_data['文章类别'].agg(conversion_data)
#********分聚组合************
# 根据'访问日期'和'用户编号'进行分组,并聚合'文章类别'列,无索引列参数['文章类别']
adjusted_data = analysis_data.groupby(['访问日期', '用户编号'])['文章类别'].sum()
# 导出表格
#adjusted_data.to_csv('C:\\Users\\raja\\Desktop\\test\\公众号用户访问数据汇总.csv',encoding='gbk')
#********支持度&置信度&提升度分析(代码简化)************
# 执行Apriori 算法
results = apriori(adjusted_data['文章类别'],min_support=0.1, min_confidence=0.3)
# 创建列表
extract_result = []
for result in results:
# 获取支持度,并保留3位小数
support = round(result.support, 3)
# 遍历ordered_statistics对象
for rule in result.ordered_statistics:
# 获取前件和后件并转成列表
head_set = list(rule.items_base)
tail_set = list(rule.items_add)
# 跳过前件为空的数据
if head_set == []:
continue
# 将前件、后件拼接成关联规则的形式
related_catogory = str(head_set)+'→'+str(tail_set)
# 提取置信度,并保留3位小数
confidence = round(rule.confidence, 3)
# 提取提升度,并保留3位小数
lift = round(rule.lift, 3)
# 将提取的数据保存到提取列表中
extract_result.append(
[related_catogory, support, confidence, lift])
# 将数据转成 DataFrame 的形式
rules_data = pd.DataFrame(extract_result, columns=[
'关联规则', '支持度', '置信度', '提升度'])
# 将数据按照“支持度”排序
sorted_by_support = rules_data.sort_values(by='支持度')
# 查看排序后的数据
sorted_by_support
#********提取出想看的数据************
# 提取出提升度大于1的数据,并重置数据的索引
promoted_rules = sorted_by_support[sorted_by_support['提升度'] > 1].reset_index(drop=True)
promoted_rules
# 提取出提升度小于 1 的数据,并重置数据的索引
promoted_rules2 = sorted_by_support[sorted_by_support['提升度'] < 1].reset_index(drop=True)
promoted_rules2
# 提取出提升度小于1的数据,并重置数据的索引
restricted_rules = sorted_by_support[sorted_by_support['提升度'] < 1].reset_index(drop=True)
restricted_rules
#********数据可视化************
# 功能:绘制提升度小于 1 的强关联规则柱状图
import matplotlib.pyplot as plt
import warnings
# 关闭警告显示
warnings.filterwarnings('ignore')
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
# 功能:绘制提升度大于 1 的强关联规则柱状图
# 设置画布尺寸
plt.figure(figsize=(20, 8))
# 设置横纵坐标以及柱子的宽度
width = 0.2
# 画出柱状图
plt.bar(promoted_rules.index-width/2, promoted_rules['支持度'], width=width)
plt.bar(promoted_rules.index+width/2, promoted_rules['置信度'], width=width)
# 设置图例
plt.legend(['支持度', '置信度'], fontsize=20)
# 设置标题
plt.title('促进关系的关联规则的支持度、置信度', fontsize=25)
# 设置刻度名称
plt.xticks(promoted_rules.index, promoted_rules['关联规则'], fontsize=15)
# 设置坐标轴标签
plt.xlabel('关联规则', fontsize=20)
plt.ylabel('数值', fontsize=20)
# 功能:绘制提升度小于 1 的强关联规则柱状图
# 设置画布尺寸
plt.figure(figsize=(20, 8))
# 画出柱状图
plt.bar(restricted_rules.index-width/2, restricted_rules['支持度'], width=width)
plt.bar(restricted_rules.index+width/2, restricted_rules['置信度'], width=width)
# 设置图例
plt.legend(['支持度', '置信度'], fontsize=20)
# 设置标题
plt.title('抑制关系的关联规则的支持度、置信度', fontsize=25)
# 设置刻度名称
plt.xticks(restricted_rules.index, restricted_rules['关联规则'], fontsize=15)
# 设置坐标轴标签
plt.xlabel('关联规则', fontsize=20)
plt.ylabel('数值', fontsize=20)
看报错应该是# 执行Apriori 算法
results = apriori(adjusted_data['文章类别'],min_support=0.1, min_confidence=0.3)
这一行的key类型不对,但是不知道怎么不对。
adjusted_data 输出的文件如下图,是CSV格式:
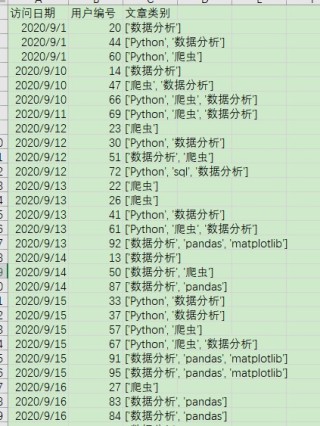
请大拿帮忙解答一下,谢谢了!