跟着教程写了个爬虫,运行后什么都没有
跟着教程写了一串代码,倒是也理解了,但修改多次以后还是这样,就是下图这个情况

是正则表达式没有匹配到结果吗。看看resp,text 的内容是否正确
如果resp,text 的内容正确 可能正则表达式写错了、
如果resp,text 的内容不正确,可能网站有反爬,可能是你requests中伪造headers的头部信息不全。
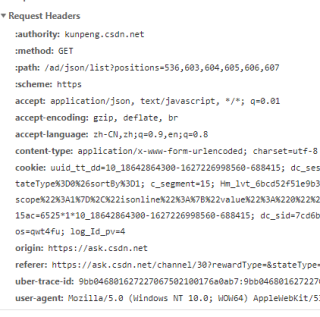
要在headers中添加抓包时的请求头求参数
比如
url = "https://xxxxxxxxxxx"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到
先看看resp.text里面有没有你要的内容,有的话就是你re写错了,没有的话就是可能被反爬了