大拿看一看>XPATH 定位不到准确位置,头发全白
船公司查询结果 http://www.fob001.cn/guestbook/chuangongsi/one.php?t=bl&c=
这个是网站,按照container No(下拉菜单). 来查找 SEGU4459419,我用selenium方法正常进去了,也搜索到了
然后我要定位返回所有的location.如下图
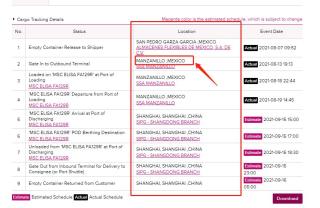
然后我就用这句话来定位 ,xpath是复制的。就改了tr。 我的理解是这样可以得到所有第三列的数据
locations=bro.find_elements_by_xpath('//*[@id="detail"]/tbody/tr/td[3]')
可是实际上locations 返回的是一个空列表。xpath也尝试了好几个写法都不行。实在不知道是为什么了,有大拿能解惑吗?干坐了俩个小时
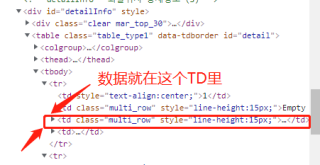
1、我觉得复制xpath没啥啊,我倒是喜欢用,真手写速度慢还容易错,我也不知道为啥都说复制不好,能准确定位就行。
2、你尝试把td打开,定位里面的元素看看,可能数据放在里面的,然后.text应该能打印出来。
3、如果只是想要爬取数据,建议直接使用requests去做爬虫,简单,而且界面影响小
复制的xpath不好,自己写。
先理解xpath语法, 一般来说, 定位元素时自己写定位方式, 有时候直接在浏览器中复制的xpath表达式不是很好用.
这个问题我后来解决了 我加了sleep(1)之后就可以了,没加的话 可能还得到了跳转前的网站代码。。。。