如何寻找hive的UDF需要继承的类?
写hive的UDF,需要继承一些类,我已经搭建好了hadoop系统,请问该如何找到需要继承的类,包括jar包,比如org.apache.hadoop.hive.ql.exec.UDF,最好来个通用的方法。
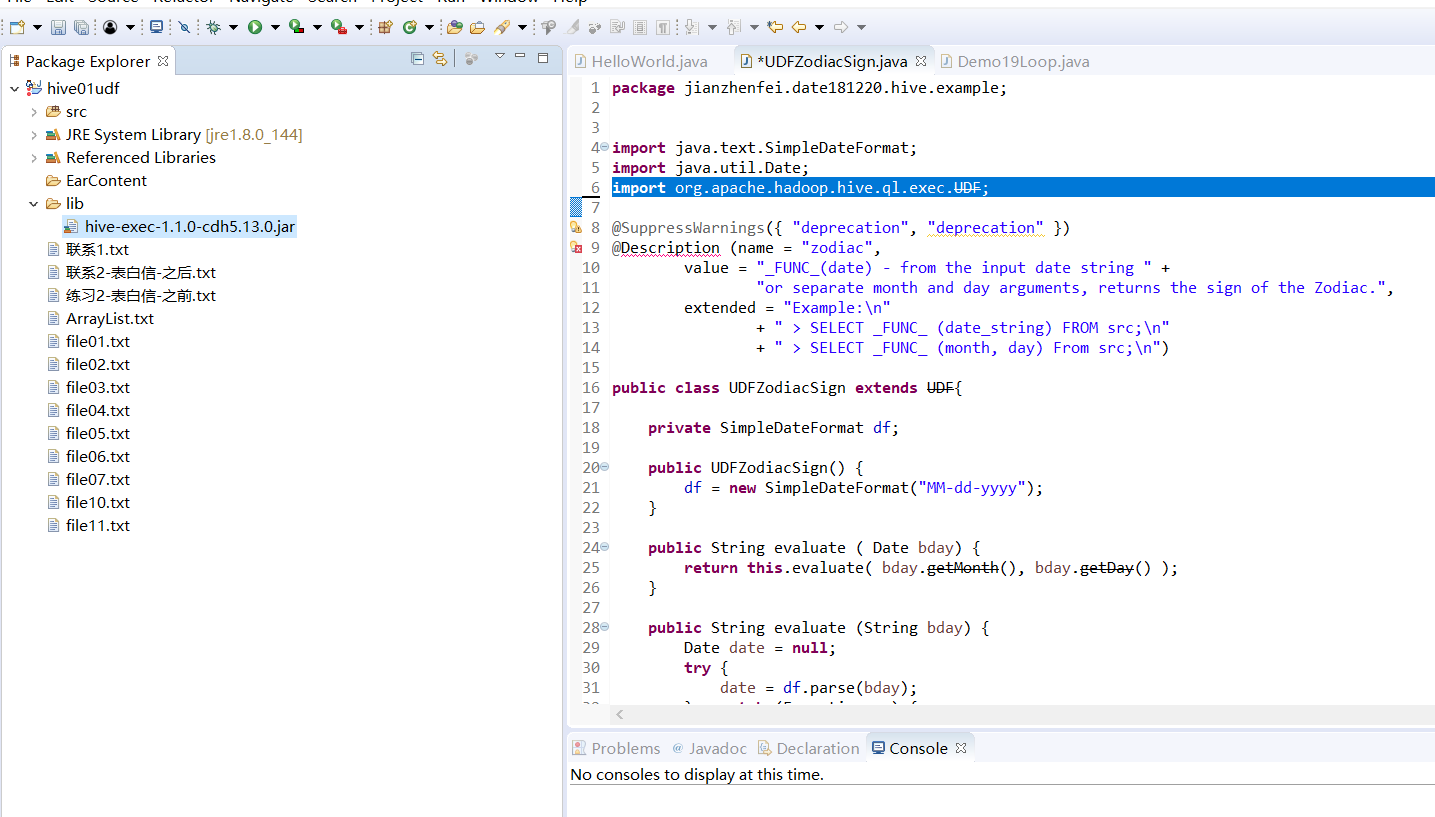
这是我目前的jar包,貌似不对...
还请大神指点迷津。
- 看下这篇博客,也许你就懂了,链接:Hive 自定义函数之 UDF 的使用
- 除此之外, 这篇博客: 数仓工具—Hive实战之UDF汉字首字母(22)中的 完整的UDF 部分也许能够解决你的问题, 你可以仔细阅读以下内容或者直接跳转源博客中阅读:
这个代码我写了很多注释,就不做过多的解释了
import net.sourceforge.pinyin4j.PinyinHelper; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.hive.ql.exec.Description; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.junit.Test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.util.Arrays; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.regex.Matcher; import java.util.regex.Pattern; @Description(name = "hanyupinyin", value = "_FUNC_(" + "String input 汉语(你)\n" + ") - return result(n)", extended = "" ) /** * 首个字符是汉语则返回拼音首字母 * 否则返回第一个字符 数字或者字母 */ public class HanYuPinYinFirstLetterUDF extends UDF { private static Map<String, String> pinyinMap = new HashMap<String, String>(); static { initPinyin("/duoyinzi_dic.txt"); } // 空则返回 空字符串 public String evaluate(String input) { if (StringUtils.isBlank(input) || input == null) { return ""; } // 不是汉语 则返回第一个字符 if (!isChinese(input)){ return input.substring(0, 1); } // 是汉语 先判断是不是多音字 if (pinyinMap.get(input) != null) { return pinyinMap.get(input).substring(0, 1); } else { // 不是多音字直接处理 char aChar = input.toCharArray()[0]; String result = PinyinHelper.toHanyuPinyinStringArray(aChar)[0]; return result.substring(0, 1); } } /** * 检查输入是否为字符串 * * @param input * @return */ public static boolean isChinese(String input) { input = input.substring(0, 1); Pattern p = Pattern.compile("[\u4e00-\u9fa5]"); Matcher m = p.matcher(input); if (m.find()) { return true; } return false; } /** * 初始化 所有的多音字词组 * * @param fileName */ public static void initPinyin(String fileName) { // 读取多音字的全部拼音表; InputStream file = PinyinHelper.class.getResourceAsStream(fileName); BufferedReader br = new BufferedReader(new InputStreamReader(file)); String s = null; try { while ((s = br.readLine()) != null) { if (s != null) { String[] arr = s.split("#"); String pinyin = arr[0]; String chinese = arr[1]; if (chinese != null) { String[] strs = chinese.split(" "); for (String str : strs) { pinyinMap.put(str, pinyin); } } } } } catch (IOException e) { e.printStackTrace(); } finally { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } @Test public void testPublicOpinionAnalysisUDF() throws HiveException { HanYuPinYinFirstLetterUDF udf = new HanYuPinYinFirstLetterUDF(); String res; res = udf.evaluate("长安"); System.out.println(res); res = udf.evaluate("长大"); System.out.println(res); res = udf.evaluate("你好"); System.out.println(res); res = udf.evaluate("ab"); System.out.println(res); } }输出结果
c z n a我们发现已经准确识别了,只不过这里是小写的,可一加一个format
如果你已经解决了该问题, 非常希望你能够分享一下解决方案, 写成博客, 将相关链接放在评论区, 以帮助更多的人 ^-^