python 验证码去除粗的干扰曲线
图1需要处理的验证码,里面包含细小圆圈噪点,和字母相差不多的曲线
灰度化,二值化处理之后得到图2
百度的OCR接口调用识别还是错误
接下来可以如何处理粗曲线呢?或者突出让验证码的边界更明显?
以下为代码
from PIL import Image
import numpy as np
from aip import AipOcr
import re,requests
APP_ID='' #这部分隐藏了
API_KEY=''
SECRET_KEY=''
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
def get_neighbor(W, H, WIDTH, HEIGH):
neighbor = []
for w in range(W - 1, W + 2):
for h in range(H - 1, H + 2):
# 边界判断
if (w >= 0 and w < WIDTH and h >= 0 and h < HEIGH):
neighbor.append((w, h))
else:
continue
return neighbor
im = Image.open('C:/Users/1/Desktop/2.png').convert('L')
W,H=im.size
im =im.point((lambda x:255 if x >180 else 0), '1')
im.show()
neighbor = None
for w in range(W):
for h in range(H):
if (im.getpixel((w, h)) == 0):
neighbor = get_neighbor(w, h, W, H)
pixel = []
for nei in neighbor:
pixel.append(im.getpixel(nei))
num_0 = pixel.count(0)
if (num_0 / 8) > 0.25:
im.putpixel((w, h), 0)
else:
im.putpixel((w, h), 255)
im.show()
im.save('C:/Users/1/Desktop/3.png')
with open(r"C:/Users/1/Desktop/3.png","rb") as f:
imag=f.read()
data=client.basicAccurate(imag)
data=str(data)
print(data)
numregex = re.compile(r"{'words': '(.*)'}")
mo = numregex.search(data)
print(mo.group(1))

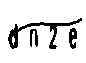
不会图像处理
直觉上是不是可以通过颜色范围分一个k-means然后对每个颜色单独识别组合
这种完全可以忽略干扰线的干扰,干扰线不会对识别产生任何影响。直接分割识别。可以参考我的博客
2021年11月最新搜狗验证码识别,6位全对正确率高达96%_Dxy1239310216的博客-CSDN博客