python 爬虫 post请求返回的数据不全,和postman模拟的不一样,关键内容是个空列表
本人小白用爬虫爬取辽宁省政府招标信息的代码如下:
import requests
import datetime
agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
head={
"User-Agent":agent,
}
url = "http://www.ccgp-liaoning.gov.cn/portalindex.do"
params = {
"method": "getPubInfoList",
"t_k": None,
}
data = {
"current": 1,
"rowCount": 10,
"searchPhrase": None,
"district": None,
"releaseDateStart": (datetime.datetime.now() + datetime.timedelta(days=-60)).strftime('%Y-%m-%d'),
"releaseDateEnd": datetime.datetime.now().strftime('%Y-%m-%d'),
"infoTypeCode": 1001,
"year": None,
"title": "柴油",
"privateOrCity": 1,
}
try:
response = requests.post(url, params=params, data=data, headers=head, timeout=10)
print(response.text)
返回结果为,rows中没有数据
{"current":1,"rowCount":10,"rows":[],"total":0}
用postman模拟相同参数请返回有数据
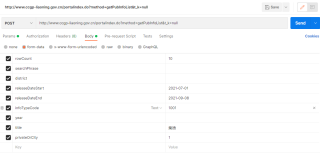
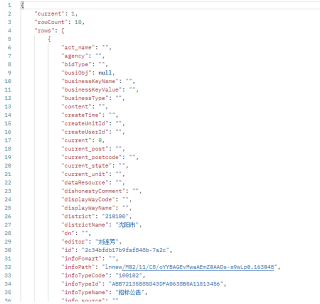
尝试过headers中加入Cookie,然而并没有用
经过实际测试,该站对 refer和 origin 没有验证,却验证了 content-type,你在header里加上content-type就可以了
import requests
import datetime
agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
head={
"User-Agent":agent,
"content-type":'application/x-www-form-urlencoded; charset=UTF-8'
}
url = "http://www.ccgp-liaoning.gov.cn/portalindex.do?method=getPubInfoList&t_k=null"
params = {
"method": "getPubInfoList",
"t_k": None,
}
data = {
"current": 1,
"rowCount": 10,
"searchPhrase": '',
"district": '',
"releaseDateStart": '',
"releaseDateEnd":'',
"infoTypeCode": 1001,
"year": '',
"title": "柴油",
"privateOrCity": 1,
}
try:
response = requests.post(url, params=params, data=data, headers=head, timeout=10)
print(response.text)
except:
print('err')
你看看你的链接是否经过处理,有些网站会需要refer来验证是不是机器在访问