Spark Task卡住的问题、Scheduler Delay 很长的问题
我写了一个label encoder的demo,逻辑很简单,从hive中读一张表(46.5M大小,很小很小),
然后对多列进行label encoder(label encoder不支持多列,使用了pipeline操作),然后从中抽取字典,最后写入hive中。
但是有个问题,就是在我执行到pipeline后面的action时,提交的作业会卡在这很久,不知道是什么原因,不可能是数据倾斜,这么小的数据。。。我对spark的调度只知表面,不知深层,请大神指点一二,谢谢各位大神。
下面是代码和ui界面:
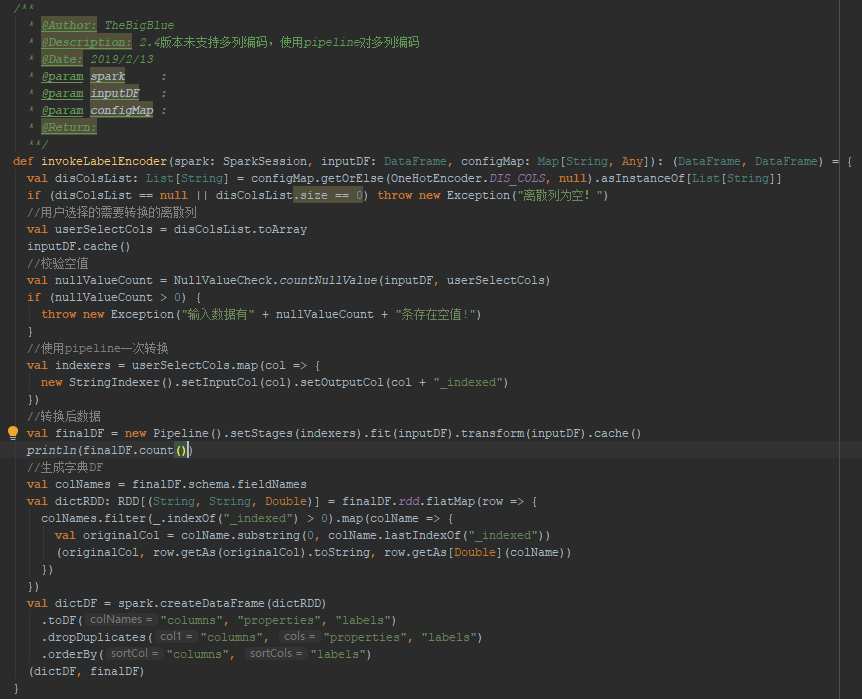
代码部分
spark ui 相关界面
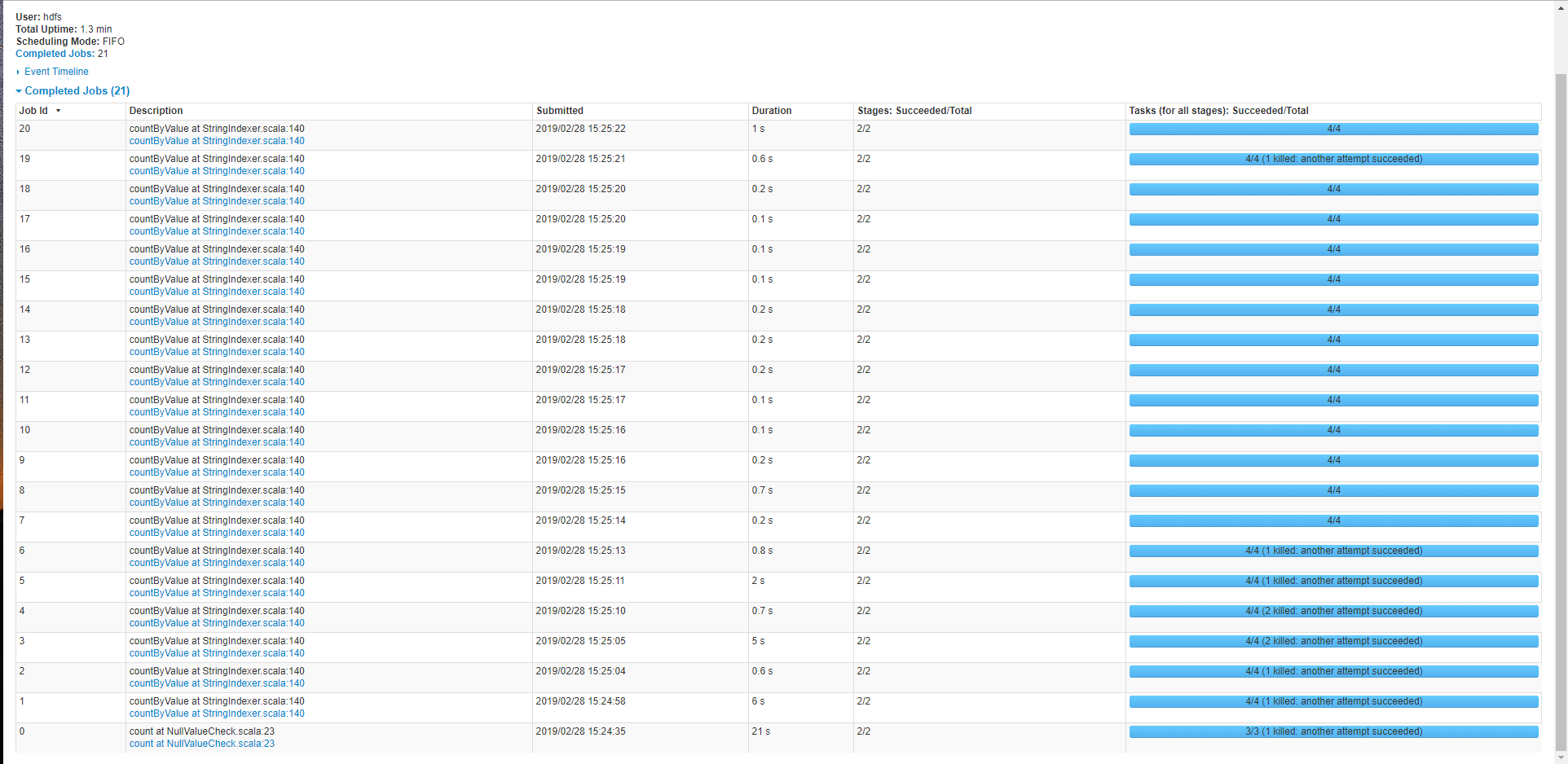
count at NullValueCheck 是校验一下空值,这个直接读取hive表,count一下,countByValue是StringIndexer类中的方法。他们的执行时间还可接受。
NullValueCheck的DAG图界面: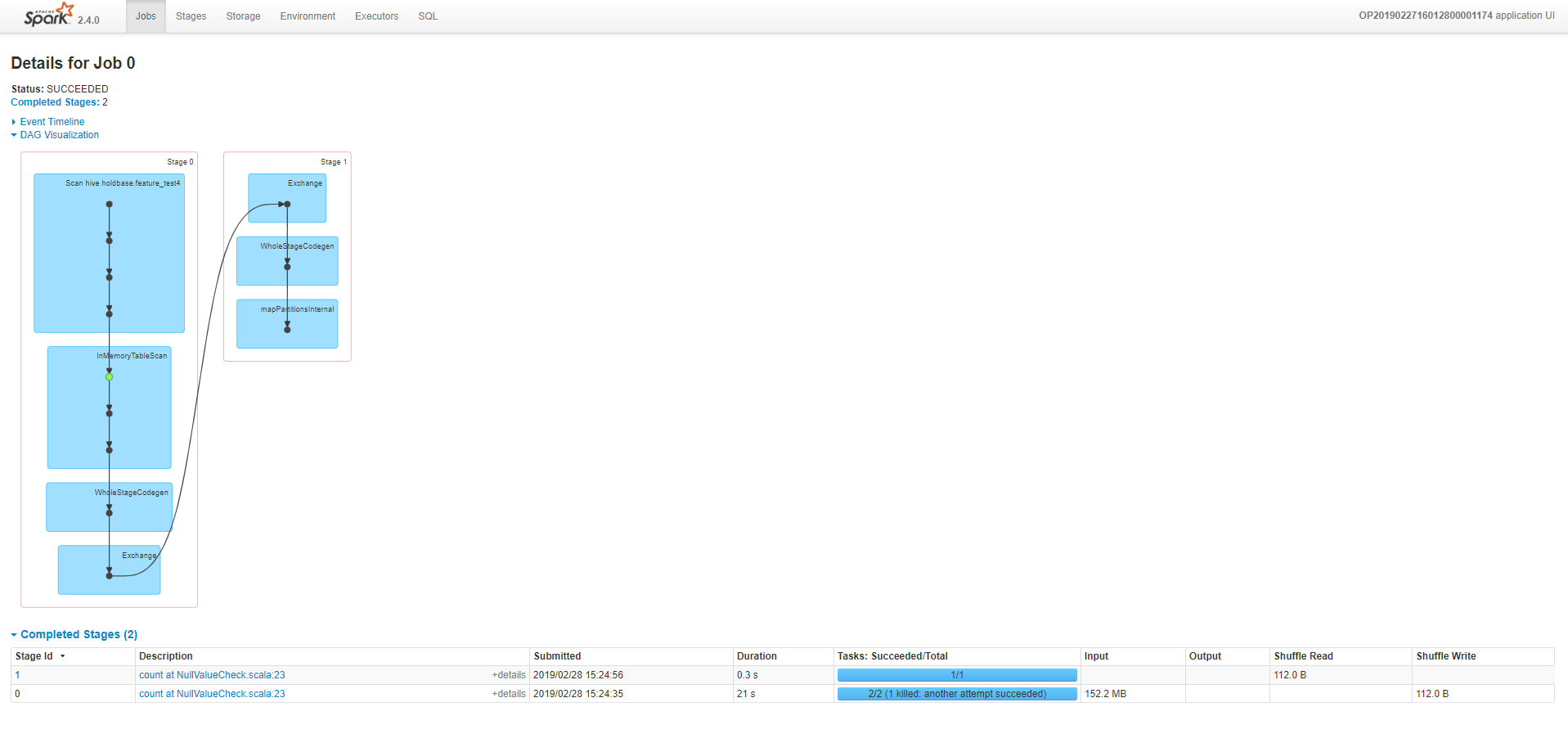
下面是countByValue方法的DAG图界面: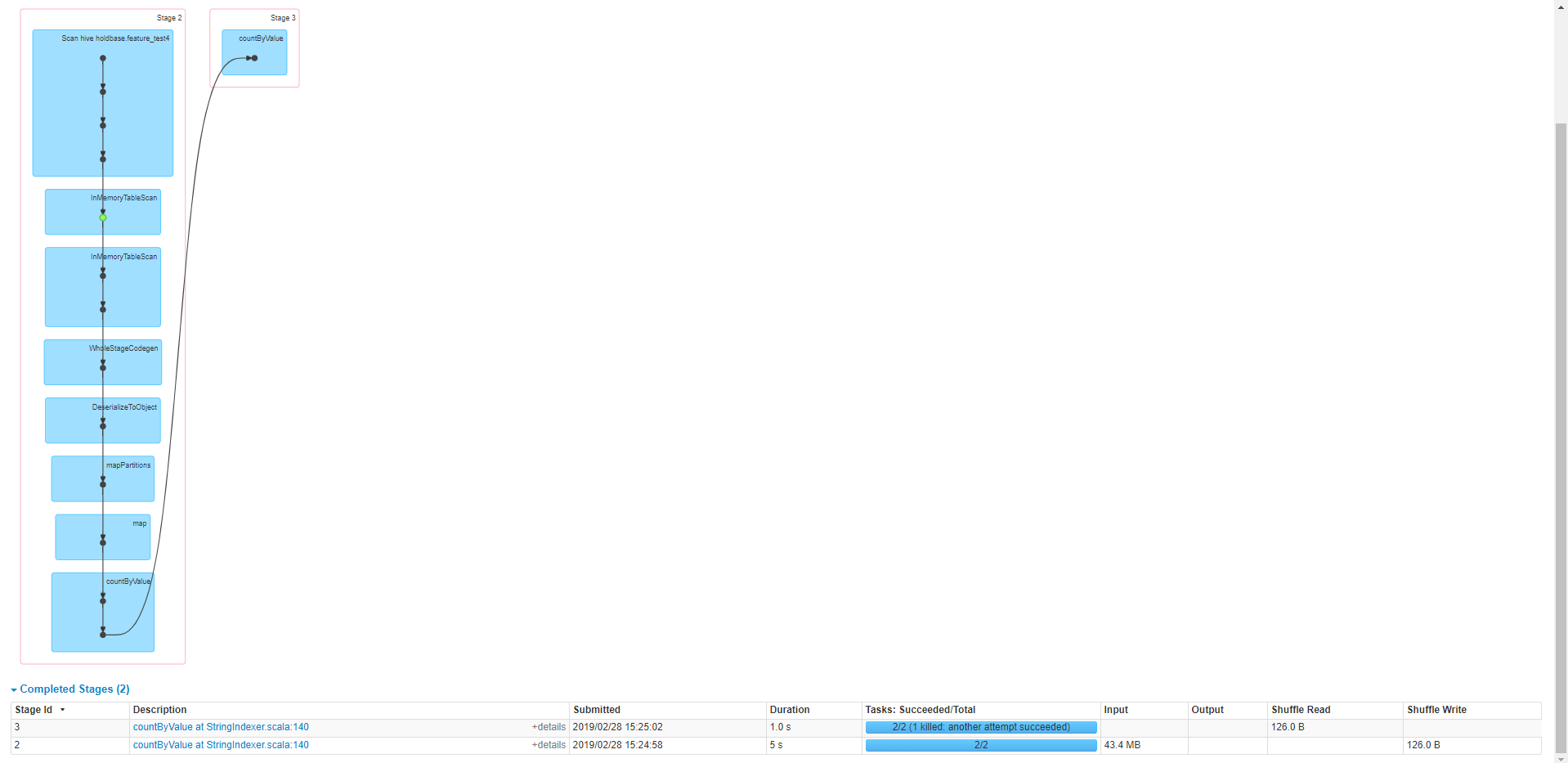
下面是count at LabelEncoder这了,这里提交了pipeline任务,然后就卡在这了:
下面两张是count at LabelEnocder job的DAG: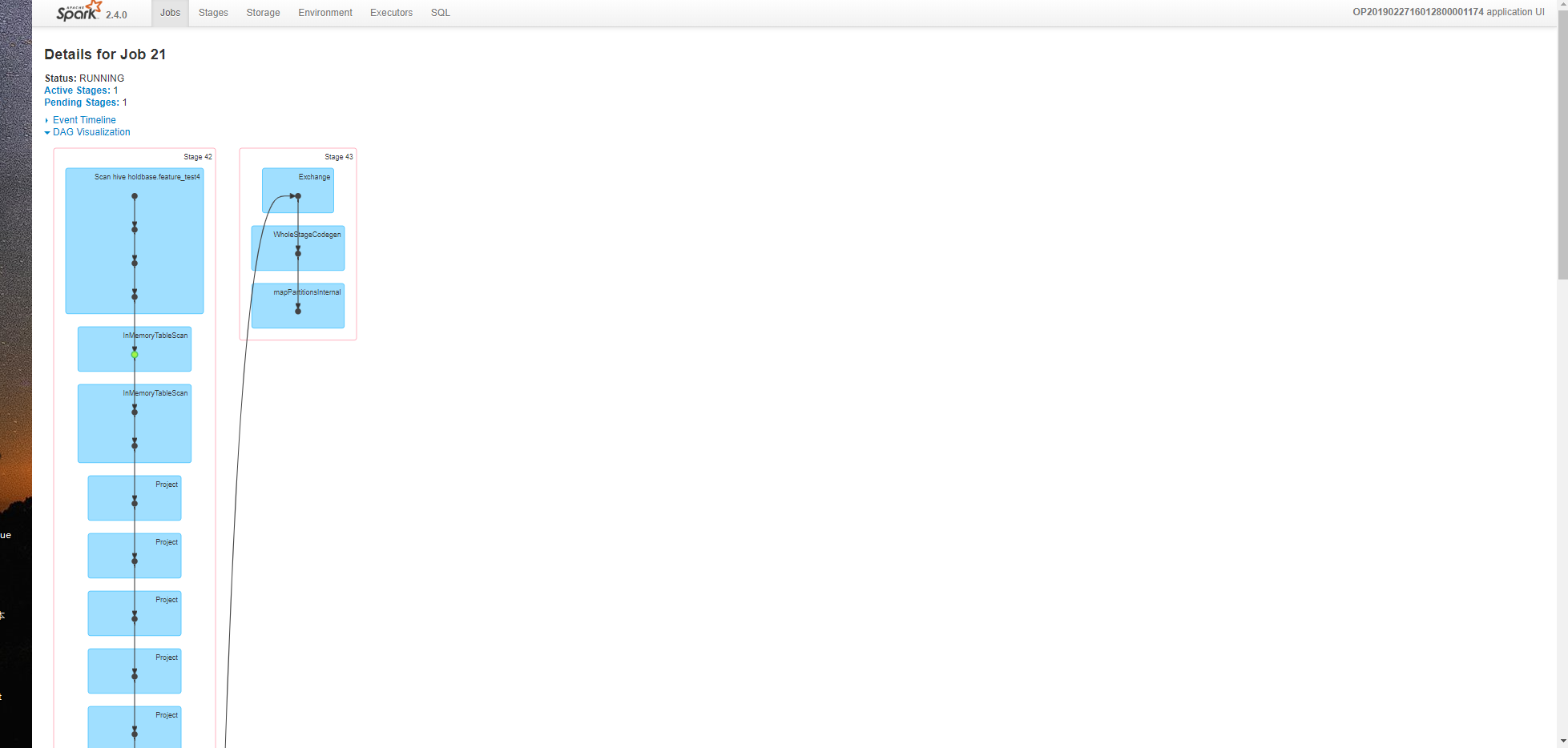
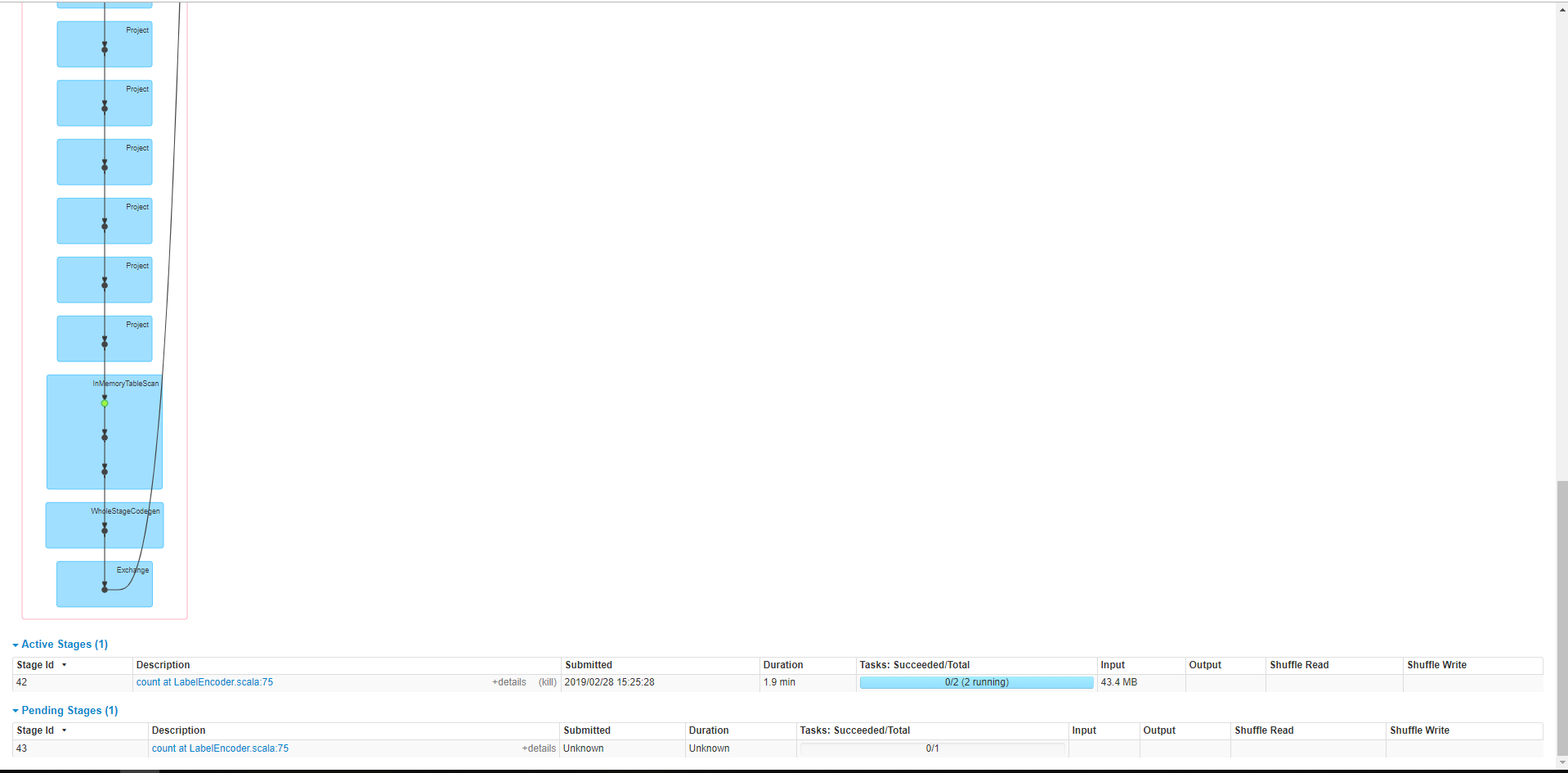
下面是这个stages界面,可以看到scheduler delay很长,task time 没有,任务卡在这了: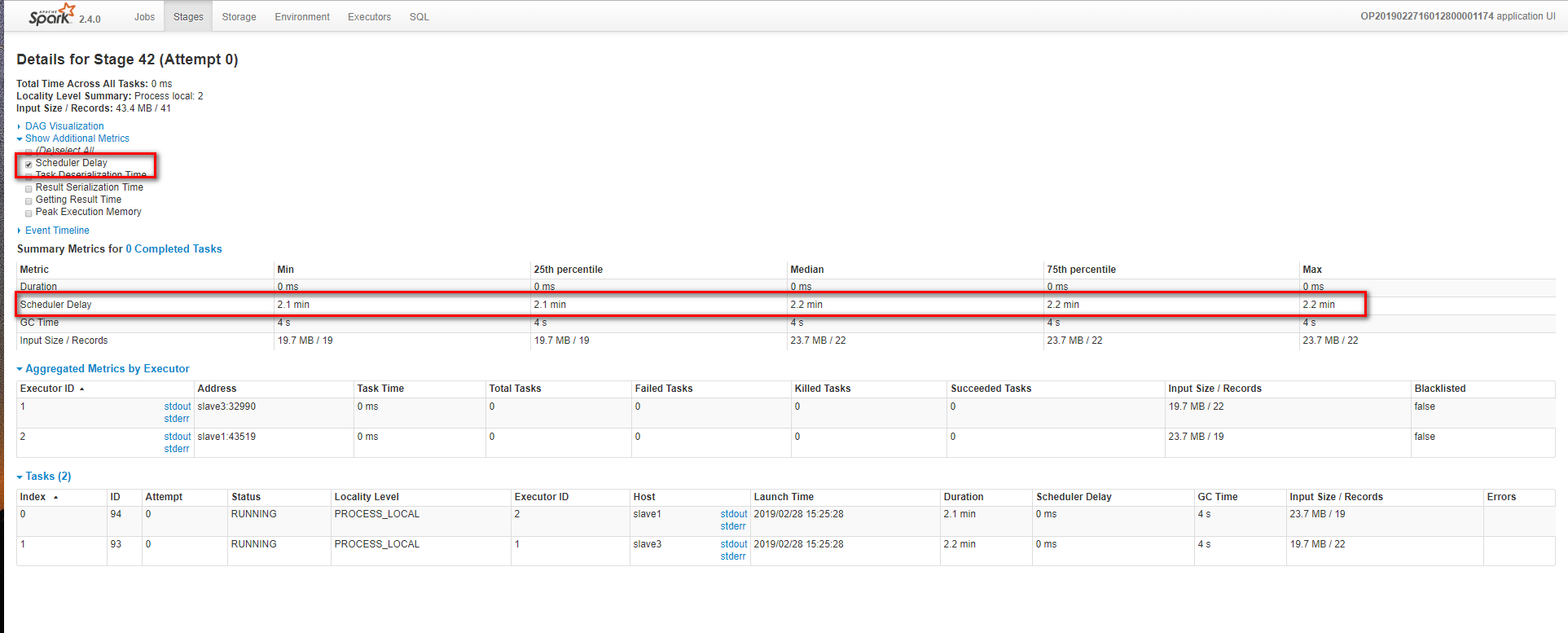
下面是executor界面供参考: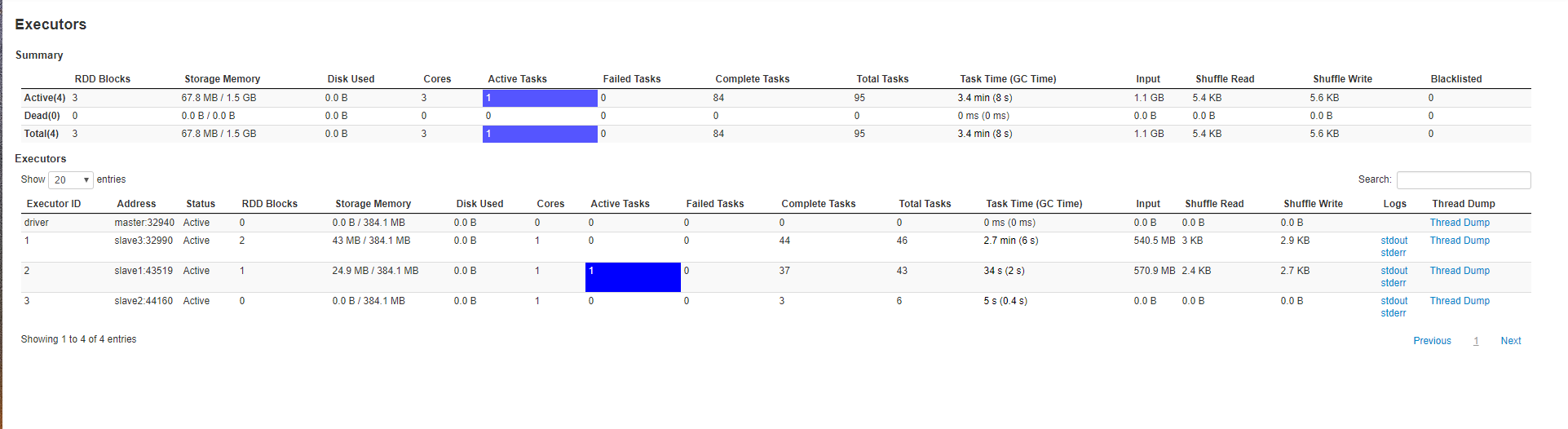
下面是这个卡住的用的总时长和后面保存表操作,可以看到这个提交pipeline任务的时间跟别的不在一个等级上,里面因为scheduler delay卡住很长时间: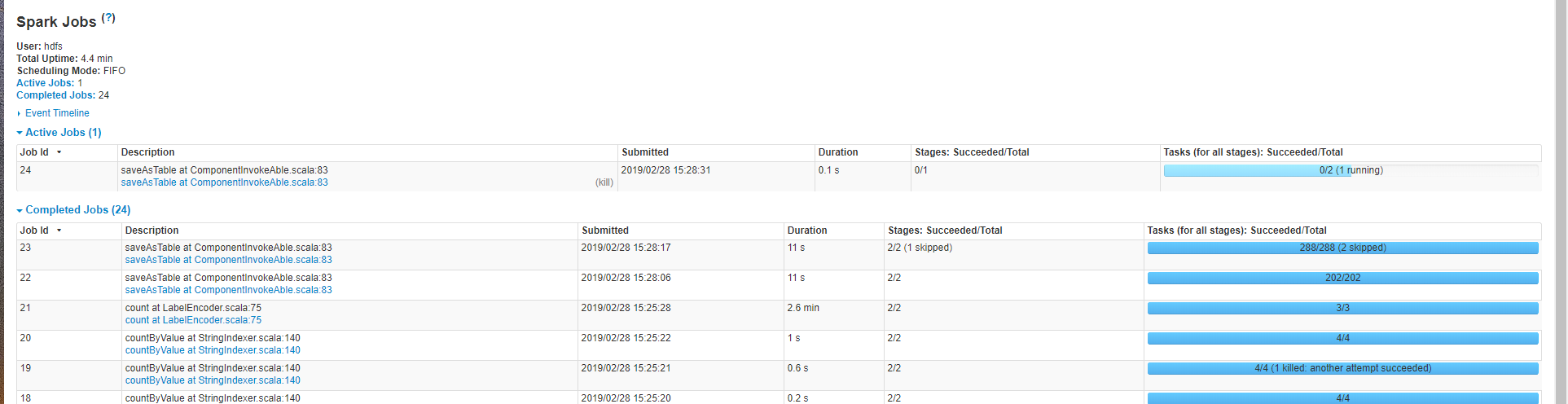
烦请各位大神帮忙看下,通过这次指导我一定能从中获取到更多spark任务相关知识,谢谢各位大神了。
我也遇到这个问题,我初步判断是小文件太多了.一个小文件启动一个task,,然后并行处理,,,,,合并小文件应该可以解决...
这个好像是显示错误,当task完成时调度延迟会变小,其实是duration时间很长。
请问这个问题解决吗,能告诉一下解决方法吗