IK 分词,当英文与数字 混合搜索时,遇到 Elasticsearch 分词问题 。
一、遇到问题的现象描述
1.1 英文和特殊字符连在一起的的分词,比如 Special Feature Note for T972-SE.pdf
1.2 使用 ik_smart 会直接分词为 t972-se.pdf
1.3 使用 ik_max_word 会分词为:
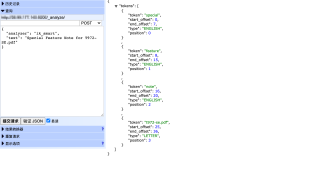
二、希望达到的效果
2.1 要求分词为 t972 和 se,且不分词成单独 t
2.2 使用的 ik 的自定义字典, 将 - 作为单词, 只对 ik_max_word 起作用,对 ik_smart 无效
2.3 要求不能 搜 t 搜出来结果
三、我尝试的解决办法
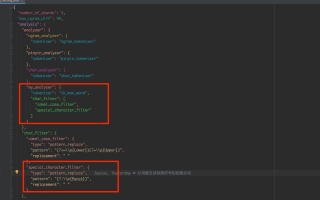
3.1 我还使用了 字符过滤器 char_filter
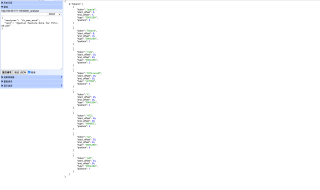
3.2 处理了特殊字符,使用的自定义分词器为 my_analyzer,也有分出单个字符
3.3 T972-SE.pdf 把这个当做分隔符,横杠,也试过。
3.4 标准分词器不能对中文分词,也不支持大小写,所以只能用IK。
四、操作环境、软件版本
4.1 IK 与 ES,都是6.4.3
4.2 操作系统使用 Linux
五、麻烦看看,如何收费
5.1 我认可知识付费。
5.2 可以根据标准,提供收费方式。
PUT /test_analyzer
{
"settings": {
"analysis": {
"analyzer": {
"test_analyzer": {
"tokenizer": "ik_max_word",
"char_filter": "patten_char_filter",
"filter": "stop_filter"
}
},
"char_filter": {
"patten_char_filter": {
"type" : "pattern_replace",
"pattern" : "-",
"replacement" : " "
}
},
"filter": {
"stop_filter": {
"type" : "stop",
"stopwords" : ["t"]
}
}
}
}
}
GET /test_analyzer/_analyze
{
"analyzer": "test_analyzer",
"text": "Special Feature Note for T972-SE.pdf"
}
启动kibana,打开开发工具
ik_smart:最少切分
GET _analyze
{
"analyzer": "ik_smart",
"text": ["中华人民共和国"]
}

ik_max_word:最细粒度划分,穷尽词库。
GET _analyze
{
"analyzer": "ik_max_word",
"text": ["中华人民共和国"]
}

我们输入文档:比如 Special Feature Note for T972-SE.pdf t和972 被分开了。
这种自己需要的词,要加到我们的分词字典中!
Ik分词器增加自己的配置
来到 elasticsearch-7.6.1\plugins\ik\config 目录下,打开IKAnalyzer.cfg.xml
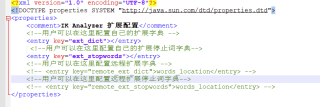
我们先创建一个dic文件,也就是字典,其实我们打开其他的dic文件也是一样的。
编写后注入到配置文件中。

然后重启es和kibana,可以看到我们新加的文件

再分词,可以发现,t972成为了单独的字段,没被细分
已上传百度网盘

使用 es 内置的 tokenizer 可以解决字母 + 数字问题。
不太懂,解析JSON后存在字典里自定义匹配切割不行么?干嘛要绕弯子。还是说你要做JSON的通配?
使用 es 内置的 tokenizer 可以解决字母 + 数字问题。是有效的,至少我这里是的