哈希表的 map.put(key,value);方法 用key取到value这个过程是怎样的?
哈希表的 map.put(key,value);方法怎么用图形理解啊
百度上说数组里存哈希值,然后接着链表/红黑树。那链表/红黑树里存的是value的话,key是不是存了数组内元素的地址,然后访问key就会访问访问到相应数组中的元素哈希值?那和直接存value不用哈希值,有啥区别啊
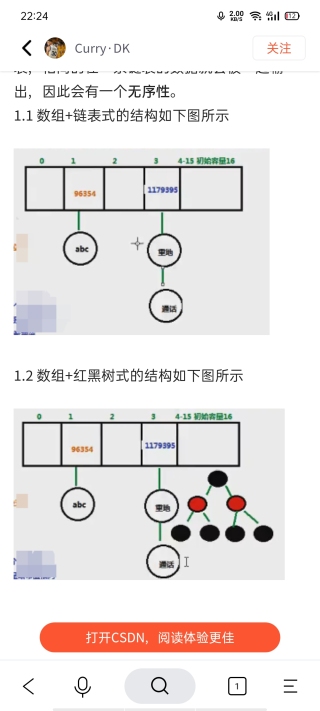
首先链表元素存的不是value,而是存的内部类Map.Node(K,V),其次节点在数组的下标运算是用key的hashCode进行一定的运算得到的。具体的运算方法可以看下这篇 从源码看HashMap 前言:HashMap是基于Hash表的Map接口实现,允许空值和空键,非线程安全的Map。HashMap不保证顺序,不保证顺序不仅仅是指存储顺序可能与插入顺序不同,还包括元素的存储位置可能会随着对实例的使用而变换。从源码看HashMap前言:1 HashMap的参数1.1 容量1.1.1 默认初始容量1.1.2 最大扩容容量1.1.3 最小树化容量1.2 装载因子1.2.1 默认装载因子1.3 阈值1.3.1 扩容阈值1.3.2 树化阈值1.3.3 树退化阈值1.4 大小1.5 modCountHash https://blog.csdn.net/yue_hu/article/details/112648241 博文的4 HashMap的下标计算算法。如果想对HashMap的实现能有进一的了解,我建议你可以花几分钟把这篇博文看完。
key不一定是地址,地址只是其中的一种可能。
比如,可以用学号做key,学生实例做value,学生类里可以包含姓名、性别、年级等等。因为一个学号对应一个学生,学号可以看做是学生的一个索引。key可以理解为value的一个快速索引。
建议看下源码,存储结构是对象数组,hash是对象数组的下标。
红黑树是更难一些的结构了。如果简单去理解。对于哈希表的 key 。 你可以理解它是数组的下标。不过这个下标不是直接拿来当下标。而是经过哈希函数转换的。
同学如果学过 C 语言的话。应该知道二维数组吧 。 你可以想象 哈希表就如同一个二维数组。第一个下标根据 Key 决定 。第二个下标可以根据存入的顺序决定(这只是其中一种思路)。
假如使用二维数据来创建一个哈希表 :
如 : { key : 123123 , value : ‘哈哈’ } ; { key:321321 , value : '呵呵' } 。 它们的 key 是不一样的 。但经过哈希函数转换。都变成了 10 ;
那么它们的位置都是在 hashList[10] 。 那么按照先后顺序 。第一个存入的在 hashList[10][1] ,第二个存入的就在 hashList[10][2]。
那么以此来理解哈希表的图就比较清晰了。
这是我的关于哈希表的理解。 但对红黑树还没有具体学习 。 一步一步来。如有不对请大佬指出
你这个是在哪里看的,感觉全乱了
map数组里面存的是Map.Entry的地址,Map.Entry里面存放key,value,如果一个hash对应了多个key,value,Map.Entry再以链表或者红黑树的方式存储,如果要通过key找到一个value是这样的过程:通过key计算出一个hash值,通过hash值定位到数组的某个位置,找到对应的Map.Entry,再匹配key,如果key相等,则返回,否则遍历链表或者红黑树查找
这块的问题涉及到数据结构相关知识,可以多了解了解,很有意思。
底层实现:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hashmap底层中,将key经过哈希函数后得到一个统一的哈希值。将哈希值作为key存储在哈希表中。
这块用到哈希函数和哈希值,是为了底层统一key的数据类型了吧,统一转为hash值。
不同的key经过hash函数后可能会得到相同的hash值, 这也就出现了hash冲突问题,解决hash冲突办法有链地址法和桶式法等。(面试经典问题)