tensorflow2.0中文手写字识别,生成tfrecord文件每次都失败,求帮助

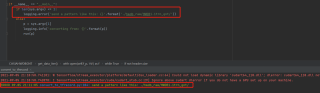
原作者说需要修改对应的路径,但是我怎么改都是这个结果,个人觉得这个结果是程序无法找到后缀为.gnt的文件。
搜索后缀是.gnt的代码是这样的:all_hwdb_gnt_files = glob.glob(os.path.join(p, '*.gnt'))
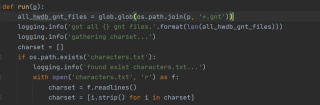
下面是我存储的路径
我在其他论坛看到有人说直接把“HWDB1.1trn_gnt”这个文件传给程序就可以了,但我改了好几次还是不行。
有无会的懂哥帮忙看一下。谢谢了

首先说下你的cuda目测没有安装正确。

其次,这行的代码是先验证你的命令行有无输入,如果没有输入就提示你输入类似的地址。
而下面的else才是正确的地址。如果你不想通过命令行来执行,那么就将if else去掉,直接将p变量赋值成你的地址就ok了。也就是
p="./xxxxx/xxxx" #
run(p)
log那句随便看你加不加,影响不大,如果有报错需要加就加上,没有也无所谓,估计你也不会看log