找到相应的url,下载就吊诡?
在下刚入坑python没多久,跟着网上的教学视频学学爬虫,最近遇见了一个问题
小的要爬取网站
https://ask.csdn.net/ysts8.net/Yshtml/Ys19115.html

然后找到第一集,并用抓包工具找到音频文件,显示的是3.2mb

这是文件链接
https://177f.wenwen120.com/%E5%88%91%E4%BE%A6%E5%8F%8D%E8%85%90/%E4%BD%99%E7%BD%AA/001.mp3
但是打开后播放的是一个11秒的文件不是要找的文件

在下作刚刚接触,遇到了第一个拦路虎,望出手
加上Referer和User-Agent就能下载了,mp3播放页面嵌在iframe里面的,来源不能设置为浏览器地址栏的url。
有帮助麻烦点个采纳【本回答右上角】,谢谢~~


import requests
url="https://177f.wenwen120.com/%E5%88%91%E4%BE%A6%E5%8F%8D%E8%85%90/%E4%BD%99%E7%BD%AA/001.mp3"
headers={"Referer":"https://ai-w-ysts8.iiszg.com/flw.asp?url=%D0%CC%D5%EC%B7%B4%B8%AF%2F%D3%E0%D7%EF%2F001%2Emp3&jiidx=/play%5F19115%5F48%5F1%5F2%2Ehtml&jiids=/play%5F19115%5F48%5F1%5F0%2Ehtml&id=19115&ji=1&said=48",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36"}
data=requests.get(url,headers=headers)
with open("001.mp3","wb") as f:
f.write(data.content)
可能是你下载文件时requests中伪造headers的头部信息不全。
要在headers中添加抓包时的请求头求参数
比如
url = "https://xxxxxxxxxxx"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36',
'Host' : 'xxxxxxxxxxx',
'Origin' : 'xxxxxxxxxxxxx',
'Referer' : 'xxxxxxxxxxxxxx',
'Cookie': 'xxxxxxxxxxxxxxxx'
}
res = requests.get(url,headers=headers)
其中请求头的参数 'User-Agent','Host','Origin', 'Referer','Cookie'可以在浏览器的f12控制台的Network中看到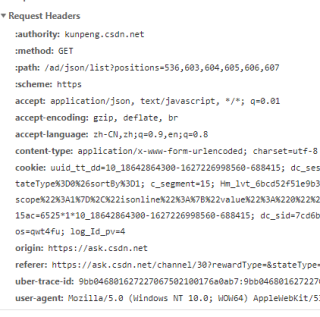
一是你选取的链接不对,先点击播放,在媒体中查找第二个链接作为requests的url,二是要将headers写全模拟浏览器播放,请求播放链接的content并写入mp3文件即可。