对原表进行upsert后,Hudi的parquet文件名中writeToken会变动,导致Incremental query失败
@[toc]
0 原因猜测
每次对原标进行upsert操作,hoodie都会产生log,然后进行compaction,从而导致该时间点以前的增量查询无法操作。
1 现象重现
下面是对原标进行的所有操作。
1.1 操作一(更新)
首先对原表进行一次upsert操作(更新370数据),然后使用增量查询,结果成功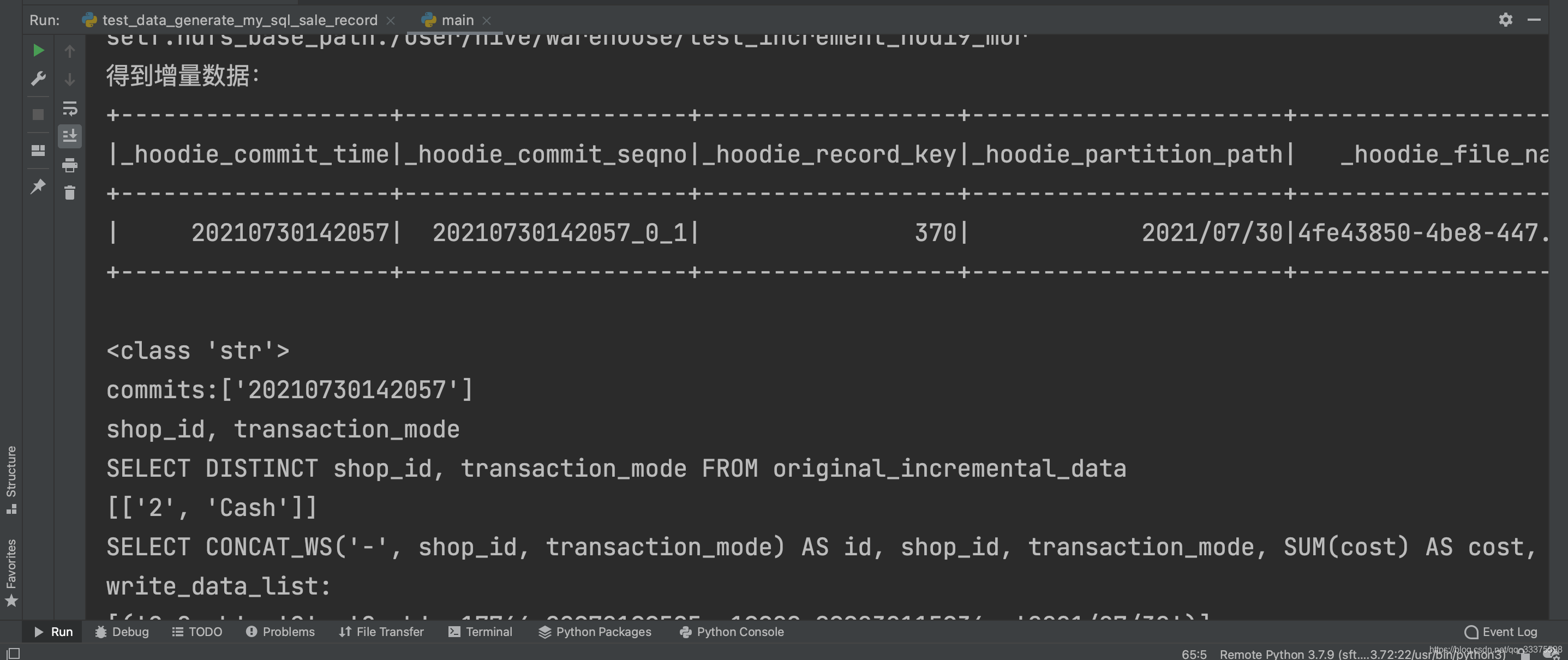
使用hadoop指令查询HDFS文件,出现log日志,数据被写到了log文件中,并未写到parquet中:

查询hoodie的详细操作,并未进行compaction操作:

1.2 操作二(插入和更新)
对原表数据进行插入6条数据并更新380数据,使用spark查询的HDFS中数据变化如下: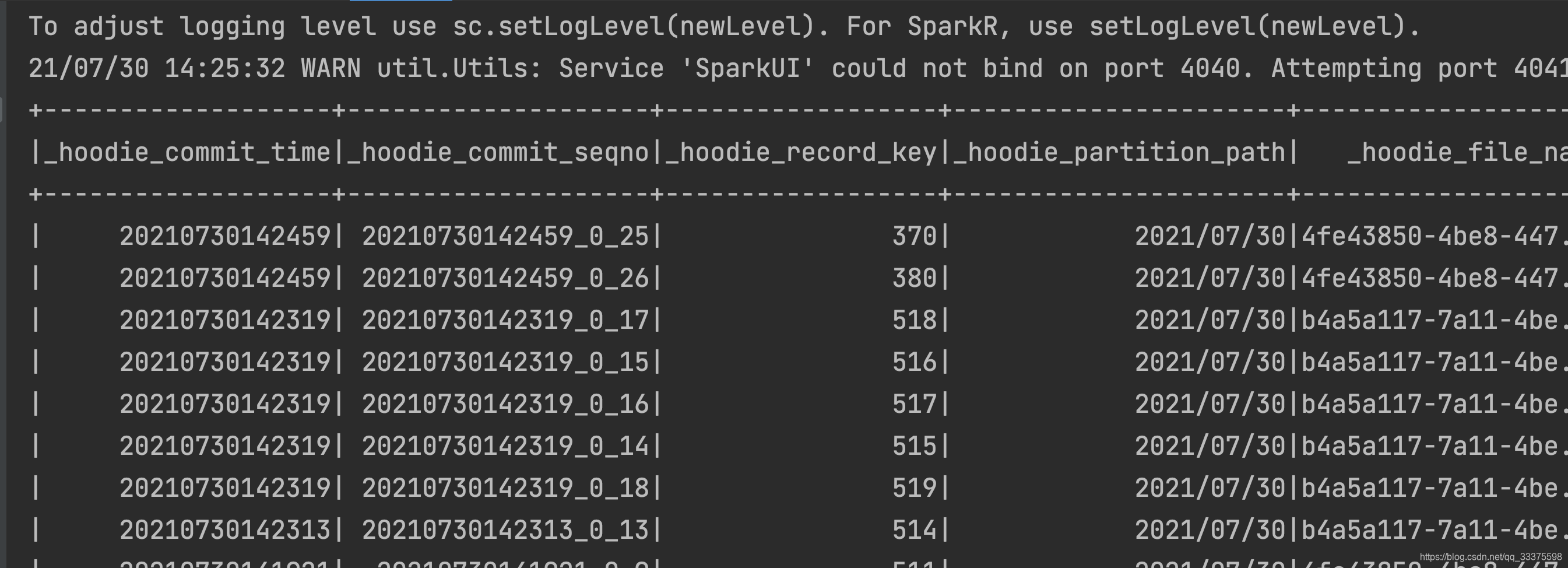
发现370数据又被重复commit。使用spark进行增量查询,曝出如下错误:
21/07/30 14:25:45 ERROR executor.Executor: Exception in task 0.0 in stage 2.0 (TID 4)
java.io.FileNotFoundException: File does not exist: hdfs://hdp-jk-1:8020/user/hive/warehouse/test_increment_hudi9_mor/2021/07/30/4fe43850-4be8-447f-827e-edfdba44adb4-0_0-340-294_20210730142459.parquet
使用hadoop指令查询instantTime的20210730142459的parquet如下,发现实际的writeToken为341-295,而进行查询的writeToken为340-294,说明了文件被再次写入了一次,导致writeToken被改变,使得spark增量查询到了一个失效或不存在的parquet文件。

查询hoodie的详细操作,发现instantTime为20210730142459的数据被compaction了一次,导致数据被重写了一次,进而writeToken被改变。

2 排除其他因素
现在只对原表数据进行insert操作,发现不产生log文件,未进行compaction操作。但是只要一对原表进行upsert操作,就会会产生log,并进行压缩。
3 解决方法
之前尝试针对错误的数据,
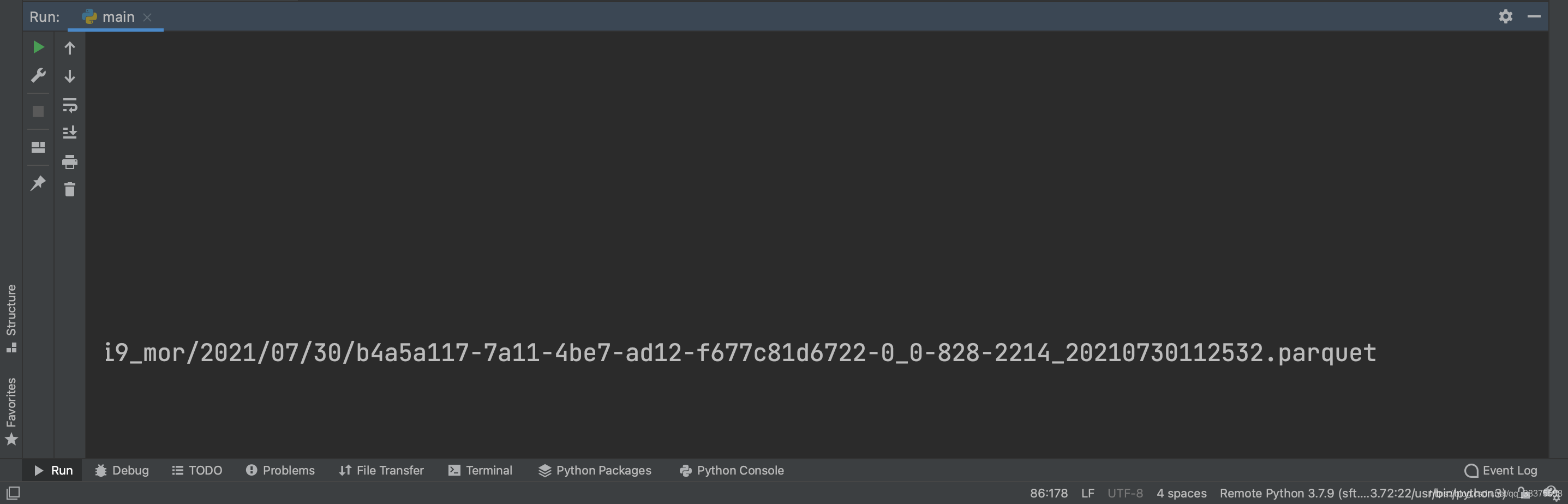
查询campaction的情况:
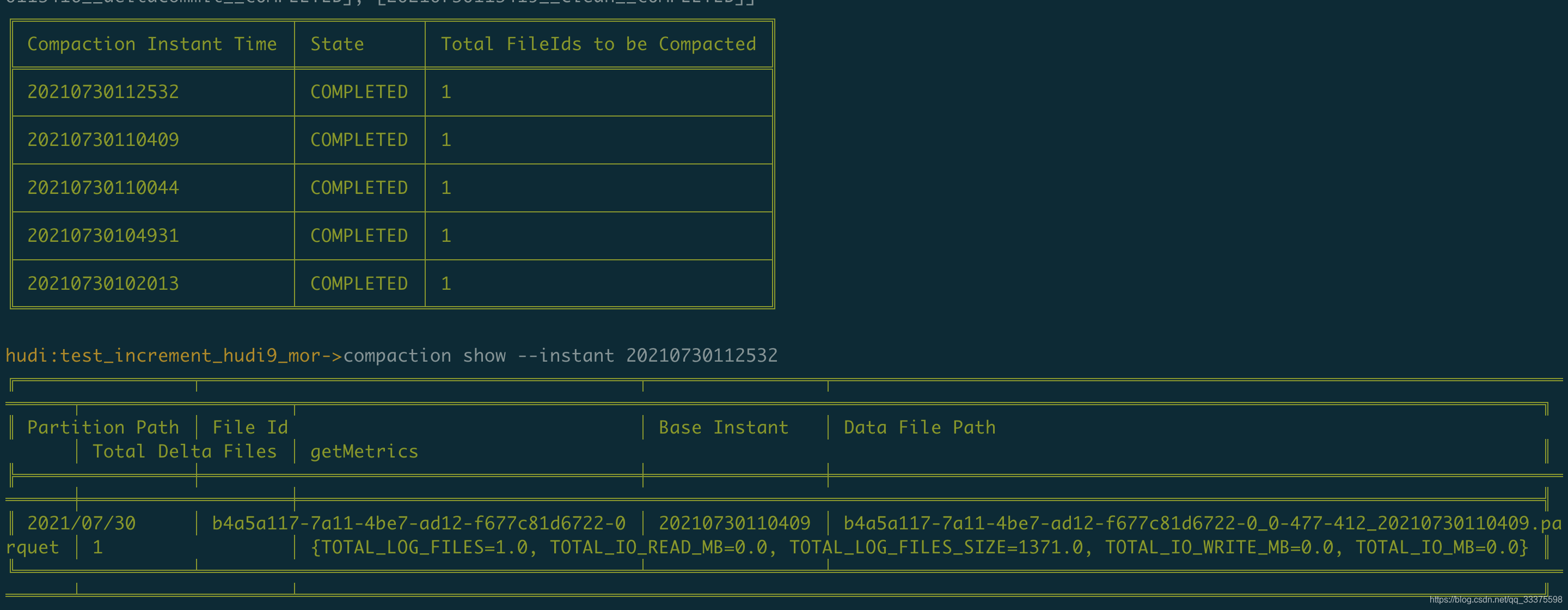
使用hudi-cli.sh中compaction repair --instant 20210730112532修复压缩,结果还是无法增量查询。
3.1 解决方法一
把对原表所有的upsert操作,都转换为insert操作。
3.2 解决方法二
调整Hudi中compaction操作,例如hoodie.compaction.strategy。目前还没有发现有用的调整策略。
目前已做尝试,但对upsert导致增量查询失败并没有帮助。
还望大家能指出正确的解决方法。
你好,我是有问必答小助手,非常抱歉,本次您提出的有问必答问题,技术专家团超时未为您做出解答
本次提问扣除的有问必答次数,将会以问答VIP体验卡(1次有问必答机会、商城购买实体图书享受95折优惠)的形式为您补发到账户。
因为有问必答VIP体验卡有效期仅有1天,您在需要使用的时候【私信】联系我,我会为您补发。