遗传距离 矩阵 来进行 K-means 聚类
如何利用遗传距离矩阵来进行K-means聚类
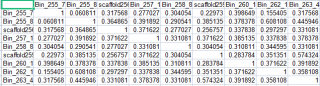
矩阵如下,横纵坐标相同,横纵坐标为标记,对标记进行K-means聚类
K-均值是发现给定数据集的k个簇的算法。簇个数k是用户给定的,每一个簇通过其质心(centroid),即簇中所有点的中心来描述。该算法是循环迭代式的。(1)初始化:随机选择K个点作为初始中心点,每个点代表一个group
(2)交替更新:计算每个点到所有中心点的距离,把最近的距离记录下来并把group赋给当前点;针对每一个group里的点,计算其平均并作为这个group的新的中心点
由于你这里不可以用欧式距离,如果用[1,2,...,9]代表类别,的话更新的点可能不在这个整数范围内,我建议选择k均值的变形--Kmedoids,同样也是先选择k,然后它更新是用簇内使用Medoids(中位数)作为新的聚点,不会溢出范围