selenium报错说陈旧的元素引用 求解
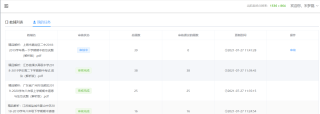
# 点击登录平台
s1 = bro.find_element_by_xpath('//*[@id="app"]/div/div/div[2]/div/div[1]/div[1]/ul/span/li[7]')
s1.click()
n = bro.window_handles # 这个时候会生成一个新窗口或新标签页的句柄,代表这个窗口的模拟driver
print('当前句柄: ', n) # 会打印所有的句柄
bro.switch_to_window(n[-1]) # driver切换至最新生产的页面
# 进入管理平台页面
s2 = bro.find_element_by_xpath('//*[@id="app-aside"]/div/div[1]/div/ul/div[5]/li')
s2.click()
# 从这里开始一直循环 自动领取教辅
while True:
# 点击教辅列表
s3 = bro.find_element_by_xpath('//*[@id="tab-list"]')
s3.click()
# 点击审核状态
s4 = bro.find_element_by_xpath('//*[@id="pane-list"]/form/div[2]/div/div/div/input')
s4.click()
# 点击待审核选项
s5 = bro.find_element_by_xpath('/html/body/div[2]/div[1]/div[1]/ul/li[1]')
s5.click()
# 点击查询
s6 = bro.find_element_by_xpath('//*[@id="pane-list"]/form/button')
s6.click()
# 点击审核
s7 = bro.find_element_by_xpath('//*[@id="pane-list"]/div[1]/div[3]/table/tbody/tr[3]/td[4]/div/button')
s7.click()
** # 点击审核能跳到新页面,但是我获取页面数据还是前一个页面数据不是新页面的,还报错说陈旧元素引用**
page_text = bro.page_source
with open('审核.html', 'w', encoding='utf-8')as fp:
fp.write(page_text)
点击“审核”后,要不试试等个几秒再获取页面源码?