遇到关于''.join吃字符串的问题
import requests
from lxml import etree
from urllib.parse import urljoin
import queue
# import threading
# import time
new_headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
url = 'http://www.biqugev.com/book/40234/'
r = requests.get(url, headers=new_headers)
r.encoding = r.apparent_encoding
html = etree.HTML(r.text)
b = html.xpath("//div[@class='listmain']/dl/dd/a/@href")
b = [urljoin(url,i) for i in b]
q = queue.Queue()
for num in range(len(b)):
qa = dict()
qa['n'] = num
qa['url'] = b[num]
q.put(qa)
def parse_text(n, url):
# print(n)
r = requests.get(url,headers=new_headers)
# print(r.status_code,r.encoding)
html = etree.HTML(r.text)
bb = html.xpath("//div[@class='content']/h1/text()")[0]
aa = html.xpath("//div[@class='content']/div[@id='content']/text()")
print(aa)
# print(bb)
aa = ''.join(aa)
print('合起来:', aa)
# time.sleep(1)
d = q.get()
parse_text(d['n'],d['url'])
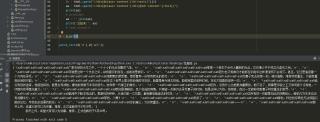
加一行代码print(len(aa))
可以看到,aa的长度很长,由此可以判断没有发送你所说的”吃字符串“的问题
在加一行代码
repr(aa)
可以看到字符中有大量的特殊符号,导致部分内容显式不出来
吃字符串什么意思